Writing Pipelets#
Python Engineer
This page describes how to write pipelets for Squirro.
This work is typically performed by python engineers, who create pipelets that project creators can use to customize their projects.
Overview#
Pipelets are Python scripts that are executed on each item before it is added to Squirro’s search index.
Pipelets are written in Python. They need to inherit from the squirro.sdk.PipeletV1 class and implement the consume() method.
The simplest possible pipelet looks like this:
from squirro.sdk import PipeletV1
class NoopPipelet(PipeletV1):
def consume(self, item):
return item
As its name says it does nothing but return the item unchanged.
Modifying Items#
Pipelets modify the item before it is returned. The item is represented as a Python dictionary. The available fields are documented in the Item Format reference. The following example illustrates modifying an item:
from squirro.sdk import PipeletV1
class ModifyTitlePipelet(PipeletV1):
def consume(self, item):
item['title'] = item.get('title', '') + ' - Hello, World!'
return item
This pipelet will modify each item it processes, appending the string “ - Hello, World!” to the title.
Skipping Items#
To skip an item (i.e., don’t add it to Squirro’s search index) return None instead of the item. For example:
from squirro.sdk import PipeletV1
class SkipItemPipelet(PipeletV1):
def consume(self, item):
if not item.get('title', '').startswith('[IMPORTANT]')
return None
return item
In this example, we discard each item if the title does not start with the string “[IMPORTANT]”.
Returning Multiple Items#
The pipelet is always called for each item individually. But in some use cases the pipelet should not just return one item but multiple ones. In those cases use the Python yield statement to return each individual item. For example:
from squirro.sdk import PipeletV1
class ExtendTitlePipelet(PipeletV1):
def consume(self, item):
for i in range(10):
new_item = dict(item)
new_item['title'] = '{0} ({1})'.format(item.get('title', ''), i)
yield new_item
Dependencies#
Pipelets are limited in what you can do. For example the print statement is disallowed and you can not import any external libraries except squirro.sdk. If you do need access to external libraries, you need to use the require() decorator. For example to log some output:
from squirro.sdk import PipeletV1, require
@require('log')
class LoggingPipelet(PipeletV1):
def consume(self, item):
self.log.debug('Processing item: %r', item['id'])
return item
As seen from the example, the @require decorator takes a name of a dependency. That dependency is then available within the pipelet class.
Use the requests dependency to execute HTTP requests. The following pipelet shows an example for sentiment detection:
from squirro.sdk import PipeletV1, require
@require('requests')
class SentimentPipelet(PipeletV1):
def consume(self, item):
text_content = ' '.join([item.get('title', ''),
item.get('body', '')])
res = self.requests.post('http://example.com/detect',
data={'text': text_content},
headers={'Accept': 'application/json'})
sentiment = res.json()['sentiment']
item.setdefault('keywords', {})['sentiment'] = [sentiment]
return item
Available Dependencies#
The following dependencies are available:
Dependency |
Description |
|---|---|
|
Non-persisted cache. |
|
Provides loggers (unstructured and structured) as class attributes: |
|
Provides access to the Python |
|
Python component which provides access to data files on disk. See Using Additional Files with Pipelets. |
Configuration#
Custom Configuration#
Pipelets can define a custom set of configuration properties by implementing the getArguments() method. The configuration properties are exposed in the UI in a user friendly form (instead of a JSON input).
The getArguments() method is expected to return an array of objects defining each property. Inside each object, the fields name, display_label and type are required. The optional field required specifies whether the property is required to be filled by the user. A property can be placed in an Advanced section of the configuration, by setting advanced to True on that property.
The type property should be one of the following: int, string, bool, password, code. The below image shows how the different types of configuration options render in the UI.
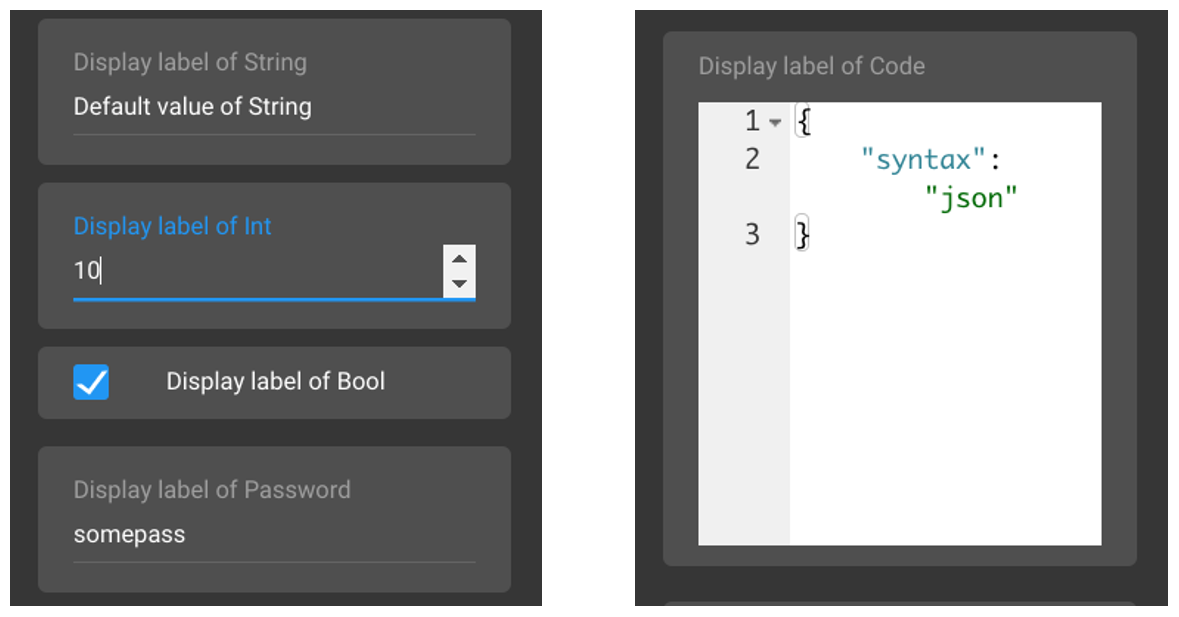
The data structure of the configuration defined in getArguments() is passed in to the pipelet constructor, where you can retrieve it. The example below illustrates how you can retrieve and set the configuration to self.conig to make it available to the pipelet instance. In this example we request the value of type str from the configuration property with name suffix and add it to the items title.
from squirro.sdk import PipeletV1
DEFAULT_SUFFIX = ' - Hello, World!'
class ModifyTitlePipelet(PipeletV1):
def __init__(self, config):
self.config = config
def consume(self, item):
suffix = self.config.get('suffix', DEFAULT_SUFFIX)
item['title'] = item.get('title', '') + suffix
return item
@staticmethod
def getArguments():
return [
{
'name': 'suffix',
'display_label': 'Suffix',
'type': 'string',
'default': DEFAULT_SUFFIX,
}
]
Note, that also a default value DEFAULT_SUFFIX is set for the suffix. This default value, as defined in the pipelet code in this example, is shown in the UI and is used as suffix if not changed.
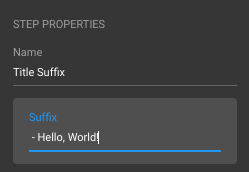
Default Configuration#
Warning
The default configuration handling is deprecated. For new pipelets please add a getArguments() method, as described in Custom Configuration.
It is recommended to always define getArguments() in the pipelet.
If it is not defined, by default a JSON editor is exposed.
Documentation#
A pipelet class is documented using doc-strings. The first sentence (separated by period) serves as a summary in the user interface.
All the remaining text is the pipelets description and is often used to document the expected configuration.
The description is parsed as Markdown (using the CommonMark dialect).
The 60-second overview serves as a good reference.
from squirro.sdk import PipeletV1
DEFAULT_SUFFIX = ' - Hello, World!'
class ModifyTitlePipelet(PipeletV1):
"""Modify item titles.
This appends a suffix to the title of each item. When no suffix is
provided, it appends the default suffix of "- Hello, World!".
"""
def __init__(self, config):
self.config = config
def consume(self, item):
suffix = self.config.get('suffix', DEFAULT_SUFFIX)
item['title'] = item.get('title', '') + suffix
return item
@staticmethod
def getArguments():
return [
{
'name': 'suffix',
'display_label': 'Suffix',
'type': 'string',
'default': DEFAULT_SUFFIX,
}
]