Setting Up Community Types#
Profile: Project Creator
This page provides instructions on setting up Community Types using the Squirro UI in your browser.
Community type set up is performed by Project Creators.
Understanding Community Types#
Communities are grouped into Community Types, which represent specific topics or themes containing multiple communities.
For example, a project that contains information about companies working in different industries might want to create community types of Companies and Sectors. Users can then choose to follow individual companies within Companies, or individual market sectors within Sectors.
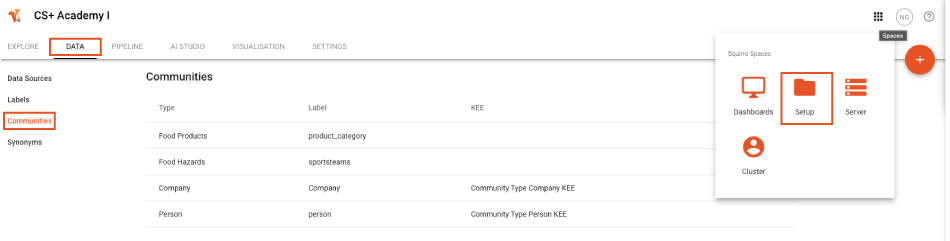
The example screenshot below shows such a setup that also includes a Country community type, which allows users to follow individual countries.

Creating Community Types#
To create a new community type, follow the steps below:
Click Setup in the top-right navigation menu.
Click the Data tab.
Click Communities in the side navigation menu.
Click Add Community or the plus-icon to create a new community type.
Add Community Fields#
The following labelled screenshot and associated descriptions describe the fields and inputs on the Add Community page:
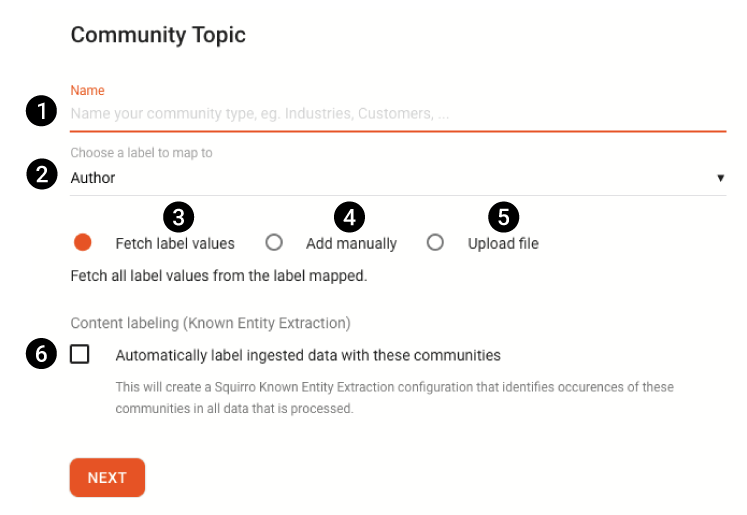
Number |
Field |
Name of the community type. |
|---|---|---|
1 |
Name |
Desired name of your new community type. |
2 |
Choose a label to map to |
The label that will be associated with your new community type. You can select an existing label or create a new one. |
3 |
Fetch label values (Add Data Option #1) |
If you selected an existing label in the previous step, selecting this option will create individual communities within your new community type based upon existing label values in the project. |
4 |
Add manually (Add Data Option #2) |
Manually enter comma-separated values, including an initial header row, to define communities in the UI text field. |
5 |
Upload file (Add Data Option #3) |
Upload a properly formatted CSV or XLSX file containing a list of your desired communities. |
6 |
Automatically label ingested data with these communities |
If selected, creates a Known Entity Extraction (KEE) that is automatically added to all pipeline workflows. Caution: Do not select this option if you mapped to an existing label that is already being generated by a KEE. This option should only be selected for new labels. |
Ways to Add Data#
There are three ways to add individual community data:
Fetching labels
Manually, or
Uploading a CSV or XLSX file.
Choose a Label to Map To#
Note
Labels are termed facets in the Squirro code. Any time the code references facets, it is referencing what the UI calls labels.
You have two options with this selection. You can either
select an existing label to map your new community type to, or
create a new label by selecting Create label… and entering a name.

Selecting an Existing Label#
If you’ve selected an existing label to map to, you can still add communities manually or upload a file containing community names, but you also have the option to Fetch label values automatically.
Tip: This is typically the preferred, time-saving approach when a label for a community type already exists.
Creating a New Label#
If you’ve created a new label, you’ll need to either upload a file listing your desired communities, enter communities manually, or enable content labelling.
Caution: Fetch label values will not work with a newly created label, as there will be no values to fetch.
Add Manually#
Comma-separated values can be manually added in the UI text field to create communities.
The first row represents headers, which should include only name, image (if required), and facet_value.
In the example input below, the communities of Netflix and Starbucks are manually added:
name,facet_value
Netflix,Netflix Inc.
Starbucks,Starbucks Corporation
Upload File#
For detailed information on uploading CSV and XLSX files, see CSV and Excel Formatting for Upload.
Content Labelling#
If selected, this option creates a Known Entity Extraction (KEE) that is automatically added to all pipeline workflows. The created KEE labels newly ingested data with the communities.
You can find and edit the KEE configuration by navigating to Setup > AI Studio > Known Entity Extraction.
The KEE configuration has the option Enable community loader set and a Community Type defined according to the name given to the created community type.
When communities are updated (when a new community is added for example), the KEE lookup database will be synchronized and updated automatically.
If you want to define communities based on a KEE, see How to Set Up Communities Using KEE.
Labelling Options#
When you select the option to automatically label ingested data, you have two options: Generical labelling and Company names labelling.
Generic Labelling#
If selected, the KEE is configured without the default company suffix list or ngram language model but requires exact matches (min_score is set to 1.0)
Company Names#
This option selects an optimized model to detect company names.
If selected, the KEE is configured using the default company suffix list and ngram language model. The min_score for matches is set to 0.6.