Squirro Classifier#
Squirro Classifier is a cutting-edge feature that harnesses the power of Named Entity Recognition (NER) to automatically identify and categorize key entities within your text data.
Squirro Classifier enables you to quickly and accurately extract valuable insights from unstructured text, including entities such as people, organizations, locations, dates, and more. With Squirro Classifier, you can unlock new levels of data understanding, streamline your analysis workflows, and make more informed decisions.
Enterprise Integration Available
Squirro Classifier can integrate with Synaptica (formerly Graphite) to make the most of your existing enterprise taxonomies. It enables standardized entity recognition using your organization’s controlled ontologies.
Key Features#
- Automatic entity identification
The system automatically detects and extracts named entities from unstructured text content, including people, organizations, locations, dates, and custom entity types defined for your specific use case.
- Categorization
The classifier enables accurate categorization of extracted entities, allowing for efficient organization and analysis of text data.
- Customization
Create and configure custom entity categories and labels tailored to your domain-specific requirements, allowing the system to recognize industry-specific terminology and organizational nomenclature.
- Integration with Synaptica knowledge graphs
Squirro Classifier seamlessly integrates with Synaptica knowledge organization systems. This powerful integration enables the use of linked labels and categories from your enterprise taxonomies, ensuring consistent entity recognition and classification aligned with organizational standards. Learn how to configure the integration
- Hybrid labeling approach
The classifier supports a combination of manual labels and categories, as well as linked labels and categories from integrated knowledge graphs.
- Pipeline integration
Squirro Classifier generates a pipelet that you can add to one or multiple pipelines, streamlining data processing workflows.
- Fast Pass feature
The Fast Pass feature enables rapid parsing of content, providing suggested labels and a foundation for manual refinement and validation.
NER Management Interface#
Squirro Classifier is a project-level configuration, meaning that named entity recognition setups are specific to each project and not shared across projects. To configure Squirro Classifier, administrators can navigate to the AI Studio space and launch the NER configuration wizard, but first, ensure that the platform contains indexed data. Squirro recommends loading a representative set of documents and data sources that reflect the final type of content the platform will ingest, as it helps ensure that the model is running on relevant data and provides accurate results.
Ground Truths#
Create and maintain a manually annotated dataset that serves as the authoritative reference for evaluating the accuracy of future content. It involves creating a new ground truth or editing an existing one, ensuring that it remains accurate and up-to-date.
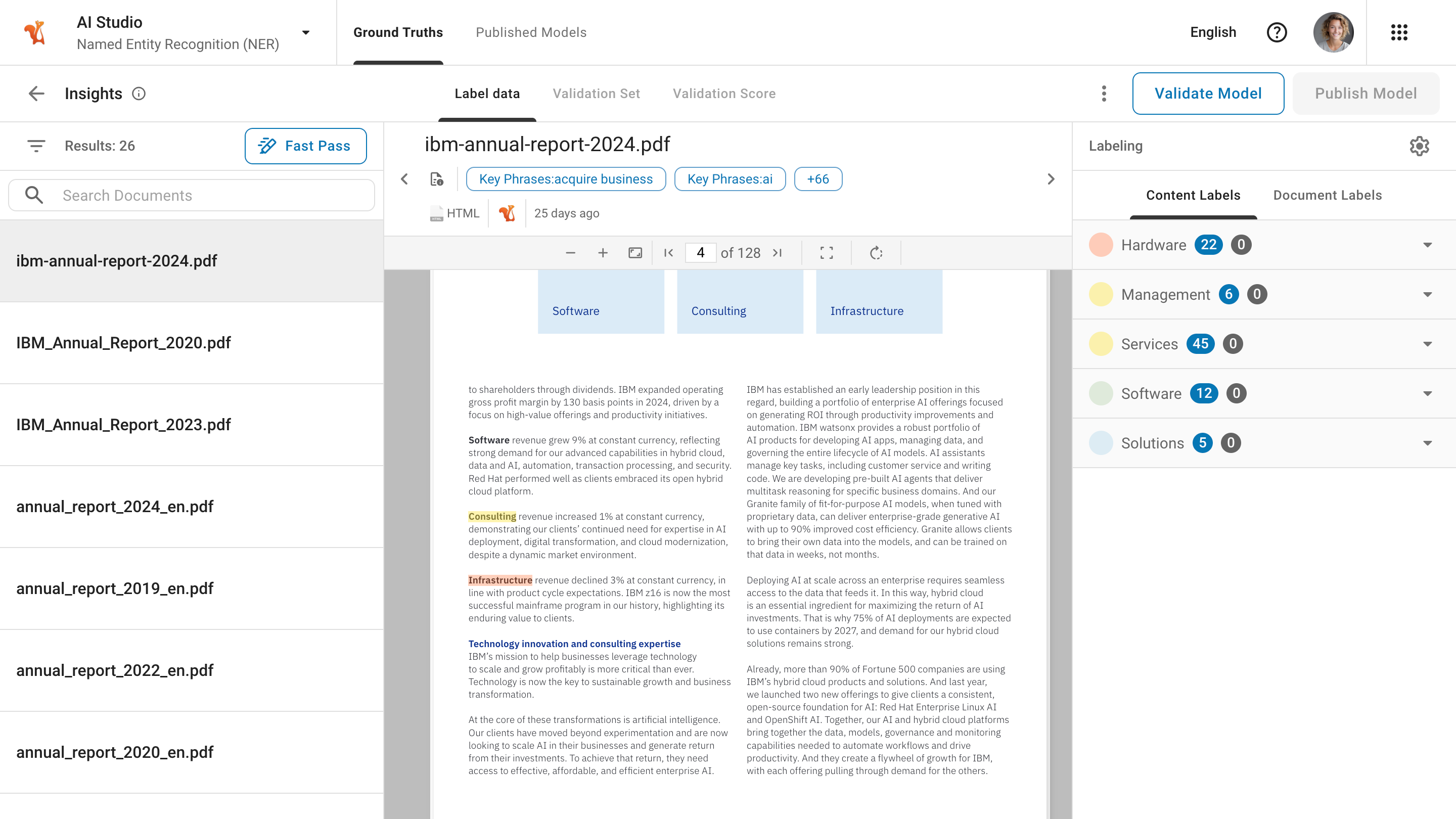
Label Data#
The label data step is the initial stage of the annotation process, marking the beginning of your journey to categorize and classify your data accurately.
When configuring categories, you have two options: manual categories and linked categories. Manual categories enable you to create custom categories with associated custom labels, offering flexibility and control over your categorization scheme.
In contrast, linked categories enable you to connect to a Synaptica knowledge graph and fetch existing categories and labels, using your pre-existing taxonomy. Synaptica integration allows you to leverage enterprise-grade knowledge organization systems, ensuring consistency across your organization’s classification efforts. When working with linked categories, you must use the labels associated with the category from your Synaptica instance and cannot create new ones. However, you can link multiple categories from a knowledge graph.
Validation Set#
The validation set step provides a comprehensive view of the applied categories and labels at both the document level and content level. This screen allows you to review the work thoroughly and make any necessary adjustments. At this stage, you can easily remove labels and their associated categories at either the document or content level. Additionally, you can quickly preview the Squirro item and view the applied categories and labels, making it easy to select and remove them if needed. This step enables you to refine and validate the categorization and labeling of your documents, ensuring accuracy and consistency.
Validation Score#
The validation score step provides key metrics to evaluate the performance of your model. One of the primary metrics is the F1 Score, which combines precision and recall into a single score, providing a comprehensive measure of your model’s accuracy.
Precision is a crucial aspect of model performance, measuring how accurately the model predicts outcomes. Precision is calculated based on two key concepts: true positives, which are entities that the model correctly identifies and classifies, and false positives, which are entities that the model incorrectly identifies as a specific type. For example, if the model identifies an entity as a person and it is a person, it is a true positive. On the other hand, if the model identifies an entity as a person but it is an organization or not an entity at all, it is a false positive.
Published Models#
The model management page provides a comprehensive list of all models created through the ground truth process, ready for production. The page displays a table with key information, including the model name and template used. From this page, you can also easily undeploy and unpublish a model, efficiently managing the lifecycle of your models and ensuring accurate deployment and updates.