Pipeline Overview#
The Squirro pipeline transforms a record from a data source to a Squirro item and writes it into the index. This page provides an overview of how it is structured and the relationships between different steps in the pipeline.
Important: A project can have one or more pipelines associated with different project data sources.
Architecture Overview#
As outlined in the Architecture, the flow of data through Squirro can be split into a number of steps:

The Load is handled by Data Loading. The data loader will give Squirro a list of records to be indexed.
The pipeline’s task is to now convert those records into properly formatted Squirro items (see Item Format) and store those items in the Squirro storage layer.
From that index, they can then be retrieved by the Squirro dashboards for visualization and searching.
Pipeline Sections#
The pipeline is split into the given sections mostly to aid understanding and configuration of the various steps.
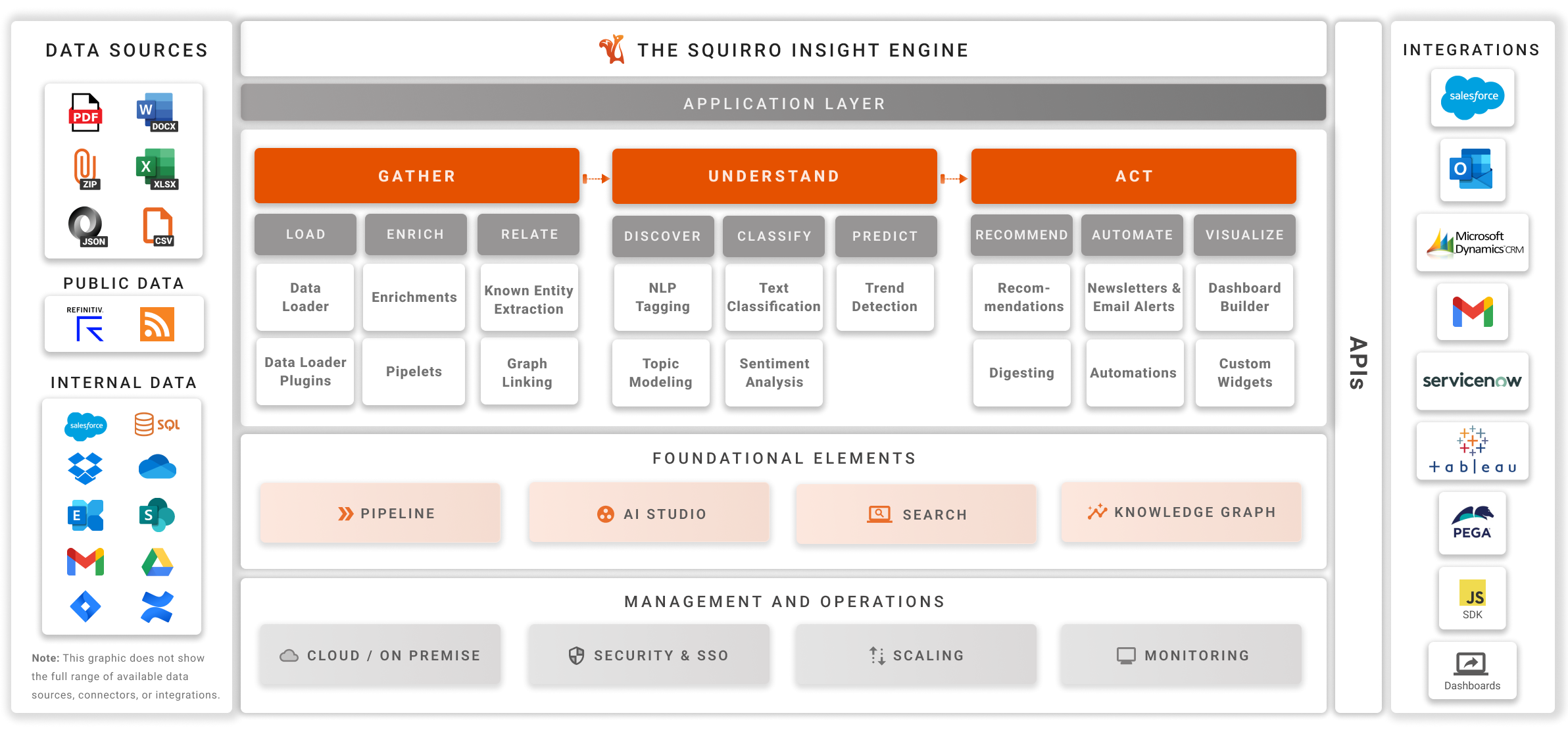
Section |
Description |
Enrich |
Extracting additional data from records or converting them into text is counted as an enrichment. This includes language detection, deduplication, or converting binary documents to text. |
Relate |
Linking the ingested items within each other or with other data sources is part of this section. Most importantly, this includes the Known Entity Extraction steps. |
Discover |
Discover includes steps around topic modeling and clustering, as well as analysis for Typeahead Suggestions. |
Classify |
Text classification, such as the models created with the Squirro AI Studio, are part of this section. |
Predict |
Predictive modeling and forecasting capabilities for data analysis. |
Recommend |
This section includes the updating of recommendation models and insights generation. These are not yet exposed in the user interface. |
Automate |
Automated actions, such as sending of emails, is included as automations. This section is empty within the user interface. |
Index |
This step is not included in the architecture charts, but can be seen and used in the pipeline editor. It includes the required steps to persist Squirro items on disk for searching. |
Custom |
Custom steps can be added to the pipeline in the form of Pipelets. These pipelets always show up in a section called Custom, but this will be extended to allow each pipelet to be assigned to one of the above sections as well. |
Ingester Service#
The ingester service is the service responsible for executing the steps of the data processing pipeline.
The ingester service receives data from the data loader, via the inputstream, and indexes it in Squirro Item Format.
From there, it executes all of the steps in the pipeline, finishing with the Indexing step as visualized in the diagram below.

Troubleshooting#
To troubleshoot issues with the ingester service, see your instance’s Squirro Monitoring space.
Note
The ingester service is not responsible for loading data. If you encounter issues with a particular data source, see Data Loading Troubleshooting.
Processing#
The pipeline steps are run sequentially. When a pipeline step fails for any reason, the item is re-queued and the full pipeline will be re-run on that item. If processing fails persistently (10 times by default) the item is dropped from the pipeline.
Some errors are handled by adding an error code to the item. The known error codes for this are documented in the Processing Errors table.
Items are only displayed to the users once the full pipeline - with exception of Search Tagging - has run through. For details on the search tagging delay, see Search Tagging and Alerting.
The sqingesterd service is responsible for executing the Pipeline workflows and their steps.
The configuration option processors under the section ingester of the /etc/squirro/ingester.ini file controls the number of processors used by the sqingesterd service to consume the batch files found under the /var/lib/squirro/inputstream directory. Each processor works on a single batch file at a time. Under the hood, each processor is a separate Unix process. The default value of this option is 1 (i.e., a single processor is spawned by the service for ingesting data).
The configuration option workers under the section processor of the /etc/squirro/ingester.ini file controls the number of threads spawned by each processor. This setting is being used for the execution of certain Pipeline steps which consume a single item from the batch at a time. Other Pipeline steps work on a batch level and therefore this option is irrelevant to them. The default value of this option is 3. (i.e., approximately 3 items of a batch are executed concurrently by a single processor).
Pipeline Step Dependencies#
Some Built-In Steps have dependencies on other steps. If these dependencies are not met, then it is possible that either the processing of the Pipeline workflow will fail completely, or it will be successful but the ingested items will not get transformed as expected. The following list outlines the current known step dependencies per section:
Enrich
The Unshorten Link step should go before the Duplicate Detection step.
The Content Augmentation step should go before the Content Extraction step.
The Content Extraction step should go before the Language Detection step.
Index
The Content Standardization step should go before the Indexing step.
The Cache Cleaning step should go after the Indexing step.
The Search Tagging and Alerting step should go after the :ref:`pipeline-steps-indexing`step.
Configuration#
A project can have one or more pipelines. Each data source is associated with one such pipeline. The pipelines are configured using the Pipeline Editor in the Setup space.