How to Create Custom Query-Processing Steps#
This page discusses the following:
How to write a custom libNLP step to extend the capabilities of the default query-processing workflow.
How to upload a new query-processing workflow to your Squirro project.
Reference: For more information about Squirro’s proprietary Natural Language Processing library, see the libNLP docs page.
Overview#
Each Squirro project is preconfigured with a default query-processing workflow containing multiple libNLP steps.
Python engineers and data scientists can create and upload custom libNLP steps to expand the workflow. This may include, but is not limited to, custom:
Boosters
Classifiers
Expanders
Language detectors
Modifiers
Parsers
Quick Summary#
To build and upload a custom libNLP query-processing step, perform the following:
Verify prerequisites are installed and available.
- Create a new folder, placing the following inside:
The JSON config file.
Your new custom step Python file.
Write your new custom step using the template.
Locally test your files.
Update the workflow within your JSON config file.
Upload to Squirro.
Squirro Profiles#
Python engineers and data scientists build and upload custom libNLP steps.
Data scientists configure and optimize existing libNLP steps for project needs.
Project creators enable and disable libNLP steps for a given project.
Squirro Products#
Custom libNLP query-processing steps are used in Squirro’s Cognitive Search and Insight Engine products.
Prerequisites#
Local Build Requirements |
Upload Requirements |
|---|---|
To build a custom libNLP step, you will require local installations of the following:
|
To upload the workflow to your Squirro project, you’ll need the following authentication information handy:
|
To download the en_core_web_sm SpaCy model, use the following command:
python -m spacy download en_core_web_sm
Workflow Structure and Templates#
Custom Step Template#
Create your custom libNLP query-processing step using the following template:
Reference: Custom Step Python Template
from squirro.lib.nlp.steps.batched_step import BatchedStep
from squirro.lib.nlp.document import Document
class MyStep(BatchedStep):
"""
Every step has to provide docstring documentation within the docstrings.
Parameters:
step (str, "custom"): What kind of step (all custom steps are labeled 'custom')
type (str, "classifier"): What category of step, classifier, tokenizer etc.
name (str, "my_classifier"): Name as it is referenced
path (str, "."): Path to step storage
"""
def process_doc(self, doc: Document):
# input & output data is accessed/written to the documents `fields` dictionary
doc.fields["my_new_tag"] = "Test"
# returned modified document
return doc
After the step has been created and tested, your workflow is then configured within config.json. The workflow can include any combination of default and custom steps.
Important: You must place your custom step file and the JSON configuration file in the same folder.
/custom_query_processing
/ config.json
/ my_query_classifier.py
Default Config File#
Use Squirro’s current default JSON Config file as shown below:
Reference: Default JSON Query Processing Workflow
1{
2 "cacheable": true,
3 "dataset": {
4 "items": []
5 },
6 "pipeline": [
7 {
8 "fields": ["query"],
9 "step": "loader",
10 "type": "squirro_item"
11 },
12 {
13 "step": "app",
14 "type": "query_processing",
15 "name": "syntax_parser"
16 },
17 {
18 "step": "app",
19 "type": "query_processing",
20 "name": "lang_detection",
21 "fallback_language": "en"
22 },
23 {
24 "step": "flow",
25 "type": "condition",
26 "condition": {
27 "healthy_nlp_service": {
28 "service": "spacy",
29 "language": "*",
30 "worker": "*"
31 }
32 },
33 "true_step": {
34 "step": "external",
35 "type": "remote_spacy",
36 "name": "remote_spacy",
37 "field_mapping": {
38 "user_terms_str": "nlp"
39 },
40 "disable_pipes__default": ["merge_noun_chunks"]
41 },
42 "false_step": {
43 "step": "app",
44 "type": "query_processing",
45 "name": "custom_spacy_normalizer",
46 "model_cache_expiration": 345600,
47 "infix_split_hyphen": false,
48 "infix_split_chars": ":<>=",
49 "merge_noun_chunks": false,
50 "merge_phrases": true,
51 "merge_entities": true,
52 "fallback_language": "en",
53 "exclude_spacy_pipes": [],
54 "spacy_model_mapping": {
55 "en": "en_core_web_sm",
56 "de": "de_core_news_sm"
57 }
58 }
59 },
60 {
61 "step": "app",
62 "type": "query_processing",
63 "name": "pos_booster",
64 "phrase_proximity_distance": 10,
65 "min_query_length": 2,
66 "pos_weight_map": {
67 "PROPN": "-",
68 "NOUN": "-",
69 "VERB": "-",
70 "ADV": "-",
71 "CCONJ": "-",
72 "ADP": "-",
73 "ADJ": "-",
74 "X": "-",
75 "NUM": "-",
76 "SYM": "-"
77 }
78 },
79 {
80 "step": "app",
81 "type": "query_processing",
82 "name": "lemma_tagger"
83 },
84 {
85 "step": "app",
86 "type": "query_processing",
87 "name": "query_classifier",
88 "model": "svm-query-classifier"
89 },
90 {
91 "date_match_on_facet": "item_created_at",
92 "date_match_rewrite_mode": "boost_query",
93 "label_lookup_match_ngram_field": true,
94 "label_lookup_fuzzy": true,
95 "label_lookup_prefix_queries": false,
96 "label_lookup_most_common_rescoring": true,
97 "label_match_category_weights": {
98 },
99 "label_lookup_rescore_parameters": {
100 },
101 "label_match_rewrite_mode": "boost_query",
102 "match_entity_phrase_slop": 1,
103 "name": "intent_detector",
104 "step": "app",
105 "type": "query_processing"
106 },
107 {
108 "step": "app",
109 "type": "query_processing",
110 "name": "query_modifier"
111 },
112 {
113 "step": "debugger",
114 "type": "log_fields",
115 "fields": [
116 "user_terms",
117 "facet_filters",
118 "pos_mutations",
119 "type",
120 "enriched_query",
121 "lemma_map"
122 ],
123 "log_level": "info"
124 }
125 ]
126}
The default query-processing steps are the following types:
step:apptype:query_processing
Example Custom Classifier Step Creation#
The example discussed in this section shows how to add a custom query classifier. The classifier allows users to search within a smaller, filtered subset of project data.
Squirro refers to this as inferred faceted search, which improves the overall search experience by returning documents that share the same topic as the user query.
In this section, you will find the following:
Example parameters.
An example Python custom classifier step.
An example JSON custom step configuration.
An example
config.jsonshowing the updated workflow with the new classifier step.
The following are example classifier parameters:
Input |
Output |
|---|---|
Query processing input: Classified label: |
|
The following is an example custom classifier step:
Reference: Example Custom Classifier Step
import functools
import logging
from squirro.lib.nlp.steps.batched_step import BatchedStep
from squirro.lib.nlp.document import Document
from squirro.lib.nlp.utils.cache import CacheDocument
from squirro.common.profiler import SlowLog
from transformers import Pipeline as ZeroShotClassifier
from transformers import pipeline
class MyClassifier(BatchedStep):
"""
Classify query into predefined classes using zero-shot-classification.
Parameters:
input_field (str, "user_terms_str"): raw user query strings
model (str, "valhalla/distilbart-mnli-12-1"): zero shot classification to use
target_facet (str): Target squirro-label used for faceted search
target_classes (list, ["stocks", "sport", "music"]): Possible classes
output_field (str, "my_classified_topic"): new facet filters to append to the query
confidence_threshold (float, 0.3): Use classified labels only if model predicted it with high enough confidence
step (str, "custom"): my classifier
type (str, "classifier"): my classifier
name (str, "my_classifier"): my classifier
path (str, "."): my classifier
"""
def quote_facet_name(self, label):
if len(label.split()) > 1:
label = f'"{label}"'
return label
@SlowLog(logger=logging.info, suffix="0-shot-classifier", threshold=100)
def process_doc(self, doc: Document):
try:
classifier: ZeroShotClassifier = self.model_cache.get_and_save_model(
self.model,
functools.partial(
pipeline, task="zero-shot-classification", model=self.model
),
)
except Exception:
logging.exception("Huggingface pipeline crashed")
# make sure that aborted tasks are not used for caching
return doc.abort_processing()
query = doc.fields.get(self.input_field)
predictions = classifier(query, self.target_classes)
value = predictions["labels"][0]
score = predictions["scores"][0]
if score > self.confidence_threshold:
doc.fields[
self.output_field
] = f"{self.target_facet}:{self.quote_facet_name(value)}"
return doc
The following is an example custom step configuration:
Reference: Custom Step Configuration
# 1) Custom step that appends writes metadata: `my_classified_topic`
{
"step": "custom",
"type": "classifier",
"name": "my_query_classifier",
"model": "valhalla/distilbart-mnli-12-1",
"target_facet":"topic",
"target_classes": ['login tutorial', 'sports', 'health care', 'merge and acquisition', 'stock market'],
"output_field": "my_classified_topic"
},
# 2) The built-in `query_modifier` step rewrites the original query based on metadata added in prior steps in the pipeline
# -> like: `query = f"{original_query} AND {my_classified_topic}"`
{
"step": "app",
"type": "query_processing",
"name": "query_modifier",
"term_mutations_metadata": [
"pos_mutations",
"my_classified_topic"
]
}
The following is an example config.json with the custom step included:
Reference: Example config.json File
1{
2 "cacheable": true,
3 "pipeline": [
4 {
5 "fields": ["query"],
6 "step": "loader",
7 "type": "squirro_item"
8 },
9 {
10 "step": "app",
11 "type": "query_processing",
12 "name": "syntax_parser"
13 },
14 {
15 "step": "app",
16 "type": "query_processing",
17 "name": "lang_detection",
18 "fallback_language": "en"
19 },
20 {
21 "step": "app",
22 "type": "query_processing",
23 "name": "custom_spacy_normalizer",
24 "infix_split_hyphen": false,
25 "infix_split_chars": ":<>=",
26 "merge_noun_chunks": false,
27 "merge_phrases": true,
28 "merge_entities": true,
29 "fallback_language": "en",
30 "exclude_spacy_pipes": [],
31 "spacy_model_mapping": {
32 "en": "en_core_web_sm",
33 "de": "de_core_news_sm"
34 }
35 },
36 {
37 "step": "app",
38 "type": "query_processing",
39 "name": "pos_booster",
40 "phrase_proximity_distance": 15,
41 "pos_weight_map": {
42 "PROPN": 10,
43 "NOUN": 10,
44 "VERB": 2,
45 "ADJ": 5,
46 "X": "-",
47 "NUM": "-",
48 "SYM": "-"
49 }
50 },
51 {
52 "step": "custom",
53 "type": "classifier",
54 "name": "my_query_classifier",
55 "model": "valhalla/distilbart-mnli-12-1",
56 "target_facet":"topic",
57 "target_classes": [
58 "login tutorial", "sports", "health care",
59 "merge and acquisition", "stock market"
60 ],
61 "output_field": "my_classified_topic"
62 },
63 {
64 "step": "app",
65 "type": "query_processing",
66 "name": "query_modifier",
67 "term_mutations_metadata": [
68 "pos_mutations",
69 "my_classified_topic"
70 ]
71 },
72 {
73 "step": "debugger",
74 "type": "log_fields",
75 "fields": [
76 "user_terms", "facet_filters", "pos_mutations",
77 "type", "enriched_query","my_classified_topic"
78 ],
79 "log_level": "info"
80 }
81 ]
82}
Local Testing#
You should test your newly created step locally during development. To do so, perform the following:
Instantiate your code.
Provide a
squirro.lib.nlp.document.Documentwith the configuration for the steps you want to test.
Example Content for Baseline Testing#
You can use the following example content to perform a simple baseline test of test_my_classifier.py:
from my_query_classifier import MyClassifier
if __name__ == "__main__":
# Documents are tagged with facet called `topic`
target_facet = "topic"
# The facet `topic` can be one of the following values from `target_classes`
target_classes = ['login tutorial', 'sports', 'health care', 'merge and acquisition', 'stock market']
# Instantiate custom classifier step
step = MyClassifier(config={
"target_facet": "topic",
"target_classes": target_classes,
})
# Setup simple test cases
queries = [
"how to connect to wlan",
"elon musk buys shares at twitter",
"main symptoms of flu vs covid"
]
for query in queries:
doc = Document(doc_id="", fields={"user_terms_str": query})
step.process_doc(doc)
print("=================")
print(f"Classified Query")
print(f"\tQuery:\t{query}")
print(f"\tLabel:\t{doc.fields.get('facet_filters')}")
Demo Output#
The following is the demo output of test_my_classifier.py:
$ python test_custom_spacy_normalizer.py
=================
Query Classified
Query: 'how to connect to wlan'
Label: 'topic:"login tutorial"'
=================
Query Classified
Query: 'elon musk buys shares at twitter'
Label: 'topic:"stock market"'
=================
Query Classified
Query: 'main symptoms of flu vs covid'
Label: 'topic:"health care"'
=================
Uploading#
Perform the following steps to upload to your Squirro project:
Upload the workflow using the following
upload_workflow.pyscript:
Reference: upload_workflow.py
import argparse
import json
from pathlib import Path
from squirro_client import SquirroClient
if __name__ == "__main__":
parser = argparse.ArgumentParser(
formatter_class=argparse.ArgumentDefaultsHelpFormatter
)
parser.add_argument(
"--cluster", required=False, help="Squirro API", default="http://localhost:80"
)
parser.add_argument("--project-id", required=True, help="Squirro project ID")
parser.add_argument("--token", required=True, help="Api Token")
parser.add_argument(
"--config", default="config.json", help="Path to workflow configuration"
)
parser.add_argument(
"--custom-steps", default=".", help="Path to custom step implementation"
)
args = parser.parse_args()
client = SquirroClient(None, None, cluster=args.cluster)
client.authenticate(refresh_token=args.token)
config = json.load(open(args.config))
client.new_machinelearning_workflow(
project_id=args.project_id,
name=config.get("name", "Uploaded Ml-Workflow"),
config=config,
ml_models=str(Path(args.custom_steps).absolute()) + "/",
type="query"
)
Execute at the location of your workflow or provide the correct path to your steps:
python upload_workflow.py --cluster=$cluster \
--project_id=$project_id \
--token=$token \
--config=config.json \
--custom_steps="."
Enabling Your Custom Workflow#
Your project creator can now enable your custom workflow from the project dashboard by completing the following steps:
Open the project in your browser.
Navigate to the AI Studio tab.
Click ML Workflows from the sidebar menu.
Hover over your step and click Set Active.
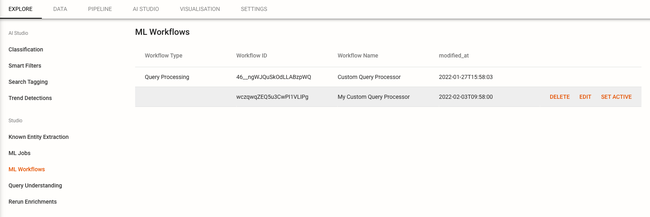
Note: You can modify the configuration on the uploaded steps by hovering over the step and clicking Edit.
Troubleshooting and FAQ#
Q1: How is the workflow executed?
Currently, the workflow is integrated into a squirro-application via the natural language understanding plugin.
The search bar first reaches out to the the natural language query plugin /parse endpoint that triggers the configured query processing workflow.
Reference: Valid Query Processing API Response
{
"original_query":"how to connect to wlan",
"language":[
"en"
],
"type":[
"question_or_statement"
],
"query":"connect^5 wlan^10",
"user_terms":[
"how",
"to",
"connect",
"to",
"wlan"
],
"facet_filters":[
],
"my_classified_topic":['topic:"login tutorial"']
}
For further information, see Query Processing.
Q2: Where can I find query processing logs?
The machinelearning service runs the configured query-processing workflow end to end and logs debugging and detailed error data.
The pipeline itself logs enriched metadata as configured via the logfielddebugger step as follows:
{
"step": "debugger",
"type": "log_fields",
"fields": [
"user_terms",
"type",
"enriched_query"
"my_classified_topic"], # appended by our classifier
"log_level": "info"
}