Semantic and Hybrid Search#
Profiles: Project Creator, Search User
Semantic search is a search technique that uses natural language processing (NLP) to understand the intent behind a query and the context in which it is being used.
Hybrid search is a combination of semantic search and traditional keyword-based search, or other scoring profiles.
This page explains the semantic search feature within Squirro, and how the semantic scoring profile is used, and discusses how Squirro Cognitive Search combines semantic search with keyword search to provide hybrid search to end users.
Feature Availability#
Semantic search is not available on any Squirro project created on a release version earlier than 3.8.4. To use this feature, you must upgrade your project to Squirro 3.8.4 or later.
Warning
Semantic search relies on the use of paragraph embeddings, which require access to a model. If you are using a Squirro Self-Service project, this is pre-configured. If you are using a Cognitive Search template on a private cloud or local installation, visit the Squirro Support website and submit a technical support request. In the interim, you may want to disable semantic search within your Cognitive Search project. To do so, see the Disabling Semantic Search section later on this page.
Overview#
Squirro semantic search goes beyond traditional keyword-based search and considers the meaning of the words used in the query.
In semantic search, Squirro retrieves results based on semantic/vector processes. This feature operates by using the scoring profile semantic, allowing users to perform approximate vector searches on paragraph embeddings.
For hybrid search, Squirro retrieves results based on semantic/vector processes, keywords, and potentially other scoring profiles as well.
It’s important to understand that while semantic search is a specific concept, hybrid search is a general term that can be used to describe any combination of search techniques. Within Squirro, hybrid search will typically include both semantic and keyword searches, but is not limited to those two alone. Other scoring profiles can be included, or other scoring profile combinations used.
Reference: Learn more about Scoring Profiles.
Important
All new Squirro Cognitive Search projects released on or after Squirro 3.8.6 LTS include hybrid search as the default search type.
Advantages and Disadvantages#
Semantic search is a powerful tool that can be used to find relevant results that may not contain the exact keywords used in the query.
Generally speaking, semantic search is smarter, more powerful, and more nuanced search.
However, semantic search is not the best fit for all use cases, and it is important to understand the disadvantages of the feature before enabling it.
The disadvantages of enabling semantic search within a project include:
Longer indexing time.
Higher storage requirements (given that documents must be broken down into paragraph embeddings which are stored separately). See the Hardware Requirements section later on this page.
Slower search speed (given that the semantic search process is more computationally intensive than keyword-based search).
If you have a project where traditional keyword search will suffice, or where speed of search is paramount, you may want to consider replacing the default hybrid search with keyword search.
How to Add Semantic or Hybrid Search to a Project#
The semantic and hybrid search is enabled by default within all new Squirro Cognitive Search projects released on or after Squirro 3.8.6 LTS. Some other projects may require you to enable the feature manually.
To enable semantic or hybrid search on a project, you must perform the following two steps:
Create the Semantic Search pipeline and use it to ingest project documents.
Add the
semanticscoring profile to the dashboard query where you want to use semantic or hybrid search.
Create Semantic Search Pipeline#
The first step in enabling semantic or hybrid search is to create the Semantic Search pipeline and use it to ingest project documents.
To do this, follow the steps below:
Open your project and navigate to the Setup space.
Open the Pipeline tab.
Click the Edit orange icon in the top right of the page.
In the bottom left choose New Pipeline to create a new pipeline.
Choose the Semantic Search workflow from the list.
Provide a new name for the newly created workflow.
Click the Save button in the top right of the page and exit.
Use the created pipeline to ingest project documents.
Caution
Any documents not ingested using the Semantic Search pipeline will not be included in semantic search.
Note
The Semantic Search pipeline is available starting from Squirro version 3.9.1. For earlier releases, add the Paragraph Embedder step to the existing pipeline in order to use semantic search.
Add Semantic Scoring Profile to Dashboard Query#
The second step in enabling semantic search is to add the semantic scoring profile to the dashboard query where you want to use semantic search.
To do this, follow the steps below:
Open your project and navigate to the Setup space.
Open the Visualization tab. (This will open a list of all dashboards in the project.)
Hover over the dashboard you want to enable semantic search within, click the three dots menu, and click Edit.
Identify the widget you want to enable semantic search within. (It will likely be an Items widget.)
Add the
semanticscoring profile to the widget’s query using syntax. The example below is the syntax used in the default Cognitive Search Global Search dashboard Items widget:
<%=
queryContext?.parse?.type === 'question_or_statement'
? 'profile:{semantic} profile:{cross-encoder} profile:{extractive-qa}'
: ''
%>
Note
This syntax checks if the provided query is the question or statement and, depending on the query, applies three scoring profiles: Semantic Search, Cross Encoding, and Question Answering.
Reference: To learn more about editing dashboards, see the Dashboard Editor documentation.
Using Semantic Search#
Once semantic or hybrid search has been enabled on a project, users should be encouraged to use natural language within their search queries, including phrasing queries as questions.
Below is an example of two widgets showing search results, where one shows semantic hybrid results and the other shows traditional keyword results.
The natural language query asks what is the film Public Housing about, as shown in the example screenshot below:
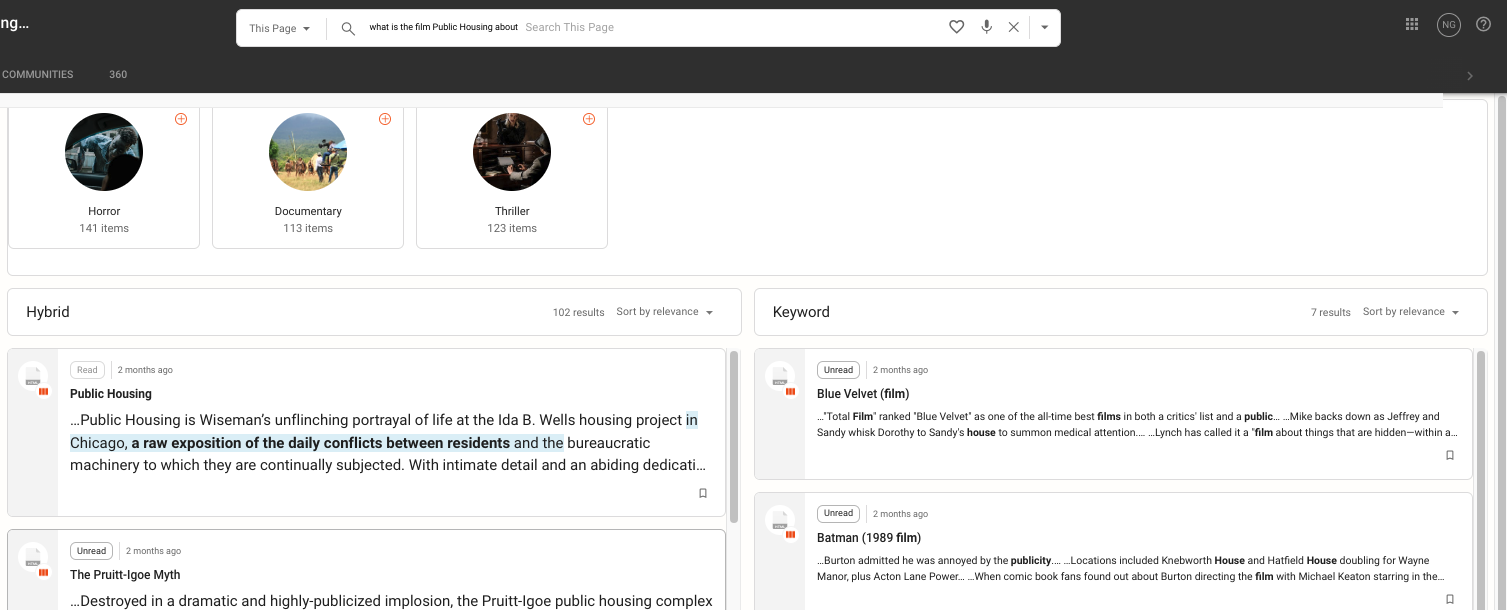
The semantic hybrid search results provide a direct answer as the first result. Part of the semantic hybrid search feature is its ability to highlight what it believes to be a possible answer when it detects the search query was formed as a question.
In the example above, you can see that it gives an exact description of the film.
The simple keyword search results, on the other hand, are not as relevant to the query.
Disabling Semantic Search#
If you would like to remove semantic (hybrid) search from your Cognitive Search project, you will need to perform the following steps:
Change your ingestion pipeline not to use the Semantic Search pipeline to ingest documents.
Remove the
semanticscoring profile from any dashboard queries where it is used.
Hardware Requirements#
The hardware requirements for semantic search depend on multiple factors, such as the number of documents, the number of paragraphs within each document, the model used to compute embeddings, and more.
It can be challenging to specify exact requirements that must be met.
However, to provide a general understanding, we can make some rough approximations.
Assumptions:
8 million documents
Each document contains 10 paragraphs
Embedding contains 384 dimensions
The data type of the embedding is float (4 bytes)
Tip
For automated calculations of the required infrastructure, check out the Semantic Search Requirements Estimation.
Storage#
Semantic search necessitates additional storage space to store embeddings.
You can compute the required storage for a single embedding field using the following equation:
Example Calculations#
Considering the provided information, the embedding will occupy:
In addition to the embedding, a document may have other fields and metadata.
For simplicity, let’s assume that the average combined size of a paragraph’s text and its metadata is 500 bytes.
With that in mind, the total storage required for all documents would be:
This means that, based on the provided assumptions, you would need a minimum of 152 GiB of storage to implement semantic search.
Storing Embeddings as Bytes Instead of Floating Points#
To reduce the required storage, you can consider storing the embedding as bytes instead of floating points.
In that case, the single embedding field size would be equal to the number of dimensions, and the final equation would be:
Memory#
To achieve efficient queries, all vector data must be held in memory.
You should ensure that data nodes have enough RAM to accommodate the vector data and index structures.
As a general rule, the number of bytes required can be calculated as follows:
Example Calculations#
Substituting the values from the assumption, the equation would be:
This means that to use semantic search for such a project, you would need at least 118 GiB of RAM.
Incorporating a Buffer for Other RAM Needs#
The data nodes should also leave a buffer for other ways in which RAM is needed.
For example, your index might also include text fields and numerics, which benefit from using the filesystem cache.
Storing Embeddings as Bytes Instead of Floating Points#
You can reduce the required RAM, by storing the embeddings as bytes.
In that case, the required memory would be closer to:
Note
Remember that these are rough estimates, and the actual hardware requirements may vary depending on factors like Elasticsearch’s internal indexing overhead, field mappings, and other settings in your Elasticsearch cluster.
Using GPU for Paragraph Embeddings#
In large-scale projects with substantial amounts of data, leveraging GPU (Graphics Processing Unit) for generating semantic search embeddings becomes imperative.
Compared to CPU (Central Processing Unit) processing, GPU acceleration significantly enhances the efficiency of generating embeddings.
Efficiency Comparison#
To highlight the significant difference in processing time between CPU and GPU, consider processing a batch of 10 paragraphs, each comprising roughly 500 tokens:
CPU Processing Time: When utilizing the CPU for this task, each batch takes around 3.8 seconds to complete the embedding generation process.
GPU Processing Time: The same batch of sentences takes approximately 0.1 seconds to generate embeddings when processed using GPU.
Note
The experiment was conducted on a server equipped with 1 Nvidia Tesla T4 GPU with 16GB GDDR6 memory. The server also featured 4 CPUs and 16GB of RAM.
Now, for further context, if we were to compute embeddings for 8 million documents, each containing 10 paragraphs:
CPU: It would take approximately 352 days to complete the computation.
GPU: In contrast, the GPU would accomplish the task in just 9 days.
Note
Provided time results consider only embeddings computation process. In real-world applications, additional factors contribute to overhead, such as network latency and other variables.
Frequently Asked Questions / Troubleshooting#
Where is the calculation of the embeddings done?
The calculation of embeddings is carried out by specialized embedding models, which operate as distinct services.
These services are engineered to function autonomously within diverse environments and are accessible by Squirro for embedding computation.
To customize the connection to these embedding services, navigate to the Server → Configuration section and make the necessary adjustments to the topic.nlp.remote-services-connection settings.
Can I switch the models used to calculate the embeddings?
Yes, the invoked model to calculate embeddings can be changed for both the data ingestion and query phases.
The model for ingesting documents can be changed in the Paragraph Embedding step within the pipeline.
Additionally, for query embeddings, you have the flexibility to specify a different worker value in the semantic scoring profile.
What search algorithm is used to perform semantic search, and what is its complexity?
The search system employs the HNSW algorithm for approximate k-nearest neighbor search, which exhibits a logarithmic scalability with a time complexity of \(O(\log N)\) in relation to the number of embeddings.
How many embeddings are created per one document?
The process of generating embeddings for a single document involves creating multiple embeddings.
This is achieved by dividing the document into smaller fragments, and then an embedding is computed for each of these fragments.
By default, the document is split at the paragraph level.
However, various chunking approaches can be configured in the Text Chunking step within the pipeline.
Can I perform only keyword search without semantic search on a project that uses hybrid search?
The search behavior is completely customizable using the query syntax, allowing for different search approaches.
You can choose to employ keyword search exclusively, semantic search exclusively, or a hybrid of both.
For instance, one dashboard widget could utilize hybrid search, while another might opt for solely keyword search.
How do the scores are combined from different queries when doing hybrid search?
When performing hybrid search, the results from both keyword search and semantic search are merged using a disjunction.
Each document’s score is determined by adding the scores from both types of queries.
Moreover, it’s possible to fine-tune the weighting of each query’s score, enabling you to prioritize one query type over the other based on your preferences.