3.11.6 LTS#
Squirro 3.11.6 was released on December 11, 2024.
Learn more about the Squirro Release Process. When upgrading between LTS releases, see the Upgrading Squirro page for important information about the sequential upgrade path.
End of support for CentOS 7 and Red Hat Enterprise Linux 7
CentOS 7 has officially reached its end of life on June 30, 2024, and is no longer supported by Squirro. To ensure the security and stability of your systems, Squirro strongly recommends migrating to a supported operating system as soon as possible. For further details on the end of support and guidance on migration options, contact Squirro Support.
Red Hat Enterprise Linux 7 entered its extended life cycle support on June 30, 2024, and is no longer supported by Squirro, although exceptions may be made for specific use cases. For further details, contact Squirro Support.
Notes for administrators
The built-in backbone widgets and the custom backbone widgets are deprecated following the introduction of their React equivalents. They are scheduled for removal in an upcoming bi-weekly release and will no longer be supported with the first LTS release of 2025. For more information, contact Squirro Support.
This release introduces important changes that may require adjustments to your existing setup. Learn more
What’s New#
Collections feature for personal groupings of indexed content. Learn more.
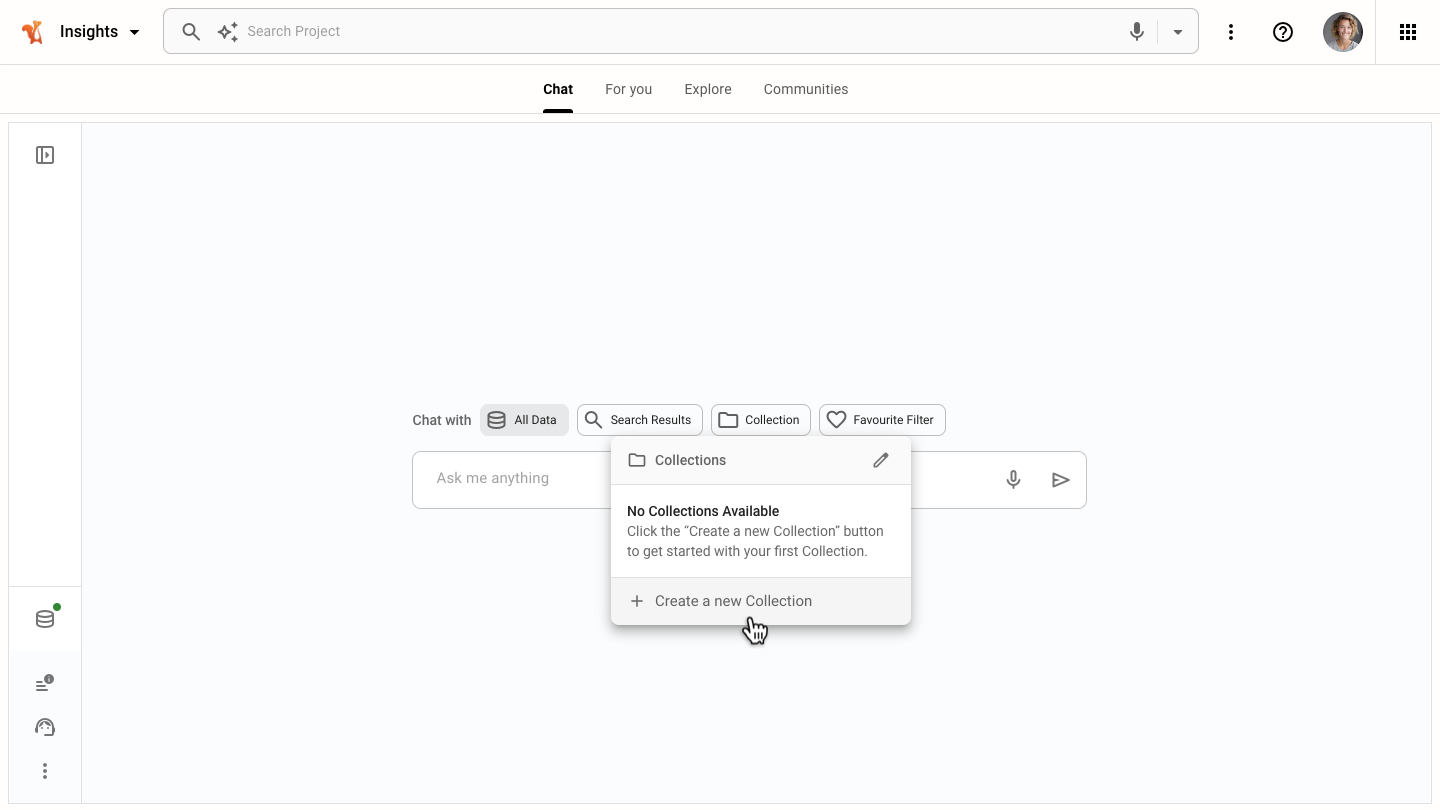
Chat with a collection of documents, search results, or favorite filters.

Summarization feature with more detailed summaries, key points, and a cleaner layout.

Support for the open-source Llama 3.1 model.
Squirro Incident Support Agent for initial assessment of support requests. Learn more
Launched Incident Support Agent as part of the multi-agent functionality.
Support for two new LLM providers, Google AI and Cerebras, available in beta.
Top-level field to store generated LLM summaries directly within each item, enabling faster retrieval and improved chat experience.
Added the possibility of injecting the necessary configuration into the genai service via environment variables.
When the queue-based filesystem streamer is used, the time required to retrieve the number of queued items of the data sources has been significantly improved. This improvement will be most evident on instances with many queued batches.
Added the project date formatting configuration, reused across the whole project.
The Label Lookup NLP step is automatically enabled during the query processing and applies potential label filters during Search Intent detection, improving search results.
The
Logsoption of a data source has been renamed toDataloader Logsto more accurately reflect its content. Additionally, a new option calledPipeline Logshas been added which allows users to view the data ingestion logs specific to this data source.The search functionality has new options for the fuzzy_match plugin, allowing the configuration of fuzzy searches to respect the order of the terms. See the FuzzyTermMatcher page for the list of possible options.
Llama tool calling using the
enable_llama_tool_callingflag.Additional description field for the data sources.
New Collections endpoints for the API.
Added accuracy and performance modes for Chat with Documents.
Introduced methods to interact with the Collections API using SquirroClient.
Added a new Llama schema for SquirroGPT configurations.
Introduced a generic prompt API for the GenAI service.
Implemented autocompletion support for the user document collections using the collection suggester.
The Paragraph Embedding step now includes an advanced option for configuring vector storage in Elasticsearch. It allows the simultaneous storage of float and byte vectors for enhanced precision and options for brute force search instead of building an HNSW graph.
The Paragraph Embedding step now includes a timeout option for the requests to the sentence embeddings service, configurable at both the step and server levels (using the
topic.nlp.remote-services-connectionoption), with the step-level settings taking precedence. It ensures that no request to the sentence embeddings service waits indefinitely, preventing ingestion delays.Introduced new
CryptKeeper``classes that resolve configuration values through environment variables using the ``CK_ENV::<value>syntax. For instance,CK_ENV::EXAMPLE_ENVfetches the value of theEXAMPLE_ENVenvironment variable.Introduced the new React Rich Text Editor widget.
The Data Ingestion Logs dashboard now displays project titles and data source names and allows filtering by both.
Search cache invalidation at the project level, through the Python client.
New retriever capable of identifying and extracting the most relevant regions for a document, and passing that information to the LLM.
Search Profiler tool available to administrators, helping them troubleshoot complex queries, analyze system performance, and gain in-depth insights into technical aspects of the search functionality.
New Reset Filters widget in React.
Widget configuration option to hide individual empty widgets.
reduce_xlsx_file option added to the PDF Conversion step.
New retriever paragraph-expansion-retriever, available in beta, as an alternative to the default squirro-retriever.
Overlap option to the Text Chunking pipeline step, allowing context preservation when paragraph splits occur.
GET /ingester/backlog/stats endpoint for frontend service web API.
Rescore parameters for the semantic search plugin to add a rescore query triggered after retrieval.
Index Manager studio plugin for basic index management.
Improvements#
AI#
Chat with Document feature rework, engage in conversations with individual Squirro items more effectively.
Added sources to the retrieved fields used by conversational AI for a more lenient context handling of summarizations.
Internal extra Llama tool calling abilities when using Cerebras models. Added context length handling in the out-of-the-box chat search, documents are trimmed when reaching the maximum token length.
Apply the hardcoded limit for the chat only to the crawler data source.
Adjusted system initial prompt to prioritize answers in the same language as the question.
Added Llama and Gemini to the context length guessing function.
Sources link to the original documents instead of the Squirro items.
StrictContextFollowingas default strategy andLenientContextFollowingas an opt-out option.
Search#
Semantic search increased performance with approximate KNN support for pre- or post-filtering profile:{ semantic knn_filter_stage:post }.
Sorting paragraph index by parent_item_id for more efficient semantic search (exact_knn) on parent-item scope (chat-with-item).
Enabled
intent_detectorto accept thelabel_lookup_rescore_parametersparameter for customized label rescoring, for example, adjustingrescore_query_weightto prioritize rescored results.Auto LabelLookup for query-intent-detection. The overall labels popularity is now used to rescore label-value` candidates. For example, how often a specific label is tagged on documents within a project contributes to the suggested label-auto-filter.
Clear the global search when the advanced search is cleared.
Added an option to turn on or off the voice recognition for the Search widget and Global Search.
Source match detection path for the search only triggered when queries are tagged as a question or statement.
Various enhancements for the paragraph-expansion-retriever squirro/tools/paragraph_expansion_retriever, including support for the chat with selection reusing the query-context as returned from query-processing (via global-searchbar).
Allow aggregation settings passed from the client.
New option to decide what text should be used to for the `Embedding Creation`encoding step.
Better handling of invalid profiles in the search query like profile:{asdf asd}.
Better handling of how properly compiled (empty) scoring profiles are treated.
Better handling of multiple empty groups.
Platform#
Introduced paragraph-scoped key phrase and NER tagging. Previously, all NLP tags were inherited from the parent item.
Enhanced the GenAI RPM package to include the Docker images as
.tar.gzfor offline installations.Properly purge dangling paragraphs when an item is re-indexed with fewer paragraphs.
Enhanced structured data ingestion logs to include the project title and data source name as labels.
Rerunning from index support for including entities in the rerun data set by default and controlled by the project-level setting datasource.rerun.index.include-entities.
The API now returns projects sorted by project-type, ensuring the default project is not the monitoring project.
When rerunning from the index using the UI, the system returns a link to directly access the Data Ingestion Logs dashboard of the Squirro Monitoring project, to check the progress of the triggered rerun job. When rerunning from the index using the SquirroClient (Python SDK), a rerun_job_id is returned in the response.
Support UFN in the data source next run.
Updating or deleting item endpoints now waits for the updating or deleting of paragraphs instead of doing it in the background.
For data loading, default to the data schema determined from the file and use the plugin schema as a fallback option.
Add the opentelemetry sqlalchemy` extension, adding tracing for the sqlalchemy` operations in the timing reports.
Avoid showing 400 errors (already paused or resumed) on data source pause or resume all.
Update the data schema to include the nested fields (for example, for the JSON data plugin).
When QFSS is configured, the ingester builds the index of queues using a background thread to avoid delaying the service bootup.
Communities cache only cleared when the synchronization mechanism changed something.
Deleting sources now consistently removes associated items from the project index, eliminating the occurrence of orphaned items.
Remaining references to Python 3.6 removed from the code base.
Added visual feedback to the labels dropdown list, with a hover border color change.
World Map widget new design and improved performance.
HTML editor upgraded to the React library.
Allowing modification of description in data sources.
Pipeline logs option in the data source rows always displayed.
The batch-level
Endof structured logs ofTransform InputandIndexingsteps now include the number of successful and errored items.Entities widget overrides and associated documentation.
namekey now included infilesfor the generated PDF files coming from thepdfconversionservice, with a value set to the filename of the generated PDF file.New configuration option for hiding the column headers inside a Table widget.
Default toast notification location changed to the bottom right corner of the page.
Elasticsearch and Filebeat upgraded to version 8.15.1.
Refined web crawling mechanism for improved efficiency and accuracy of website data extraction.
When using the queue-based filesystem streamer (QFSS), the source queue statistics from Redis are now deleted upon data source deletion. In addition, when the index of queues is built, the queue statistics are updated.
Ensured application of the project visual theme before the page loads, eliminating the transient display of non-themed content.
Added support for
*.ppsxand*.potxfiles (PowerPoint slideshows and templates).Forwarding of all payload arguments to
model_extras, allowing access tochat_historywithin a tool.Improved
context_guessingfunctionality for unnamed models.Improved keyword sorting by displaying the value in item views.
Automatic expansion option for the time selection widget.
Increased default timeout for query processing workflows, allowing LLM calls.
In pipelets, the log dependency adds the new attribute dlog, which logs in an unstructured format in the plumber.log files and a structured one in the Data Ingestion Logs dashboard.
PDF zoom level saved when switching items in Document Details.
Added embedding truncation and more control to the vector quantization (float32, int8, uint8, binary, ubinary).
Enable scoring plugins to also work at the rescoring stage, by specifying stage:rescore within the profile:{}.
Allow customizing of getHighchartsOptions for the HeatMap react widget.
Added a new empty state for the My communities widget, with a new follow communities modal.
When ingesting data with a pipeline that includes pipelets, any exceptions raised within the pipelets are now displayed on the Data Ingestion Logs dashboard.
Added a retriever state to apply different retrieval approaches.
More detailed error messages for the JSON dataloader.
The project create dialog and selector migrated to React.
Dashboard navigation tabs migrated to React.
Rerunning from index now supports the batch priority for the rerun data, by default with normal priority.
List option tooltip for the Filter widgets only appears when content overflows.
Hide widgets when empty in auto-expandable accordion mode.
SharePoint connector support for ACLs using internal SharePoint groups and users, using one
dataloading.get-microsoft-user-groupsconfiguration option.Hide Reset Filters widget when empty.
Reset Filters widget by default in List mode.
User profile picture displayed as a rounded image.
Add basic GitHub token validation to the form field.
Show full date with hours in items tooltips.
OpenJDK upgraded to the latest LTS version.
When using Squirro Toolbox, informative error messages are now printed when the selected metadata database directory cannot be created or is not writable.
Bug Fixes#
Removed fallback data schema when retrieving schema using the data plugin method to prevent duplicate validation.
Item detail no longer opens on every dashboard selection change.
Fixed the max width issue with the keywords table popup in the Items widget.
Custom datetime facets are formatted correctly in the ItemsTable widget.
The items table columns are resizable.
Correctly handle an invalid query_context.parse value.
The pdfconversion service no longer fails to convert files with long filenames of more than 150 characters.
Assume some query parts can be functions for item query construction.
The Explore button on data sources works as expected.
Fixed items widget reacting to
activeItemchanges when it should be hidden.The
ItemsTablesort by date works as expected.Labels automatic expansion.
Addressed issue when handling dashboard filters with an empty query.
Proper migration script applied during paragraph mapping, adding a new
positionfield to the existing indices.Fixed the storybook documentation pages not showing up in the final build.
Use the vertical card hover state for the Items Grid mode.
Fixed issue with the Documents connector, also known as
filesystemplugin, where multiple copies of the loaded source file were stored in/tmpdirectories.Ensure the Collections profile matches no items if a collection is empty and no interference from cached results when using queries with the
collectionprofile.Lifted restrictions about what kind of strings to map to an
sqsortfield to fix a bug that would occur when indexing documents containing a title, body, or summary that look like dates or plain integers.Adjusted system query for the Collections profile to also account for results in the paragraph index.
SimilarSearch widget header style no longer differs from other widgets.
ItemDetail widget experienced some cases where item labels did not load.
Summarization now respects the persona and language settings.
Fixed handling of sorting features and other complex query clauses for dashboard or community filters.
Additional queries incorrectly managed by the Entities widget.
Connection widget selection not fully removed from a reset widget.
Missing language and persona instructions for the starter questions.
Issue with overriding tool name and description for the retriever tool abstraction.
Incorrect formatting of language and source labels in the ItemsTable widget.
Crawler downloading of PDF files protected by HTTP authentication.
Multiple modals opened when using a share link to Document Details.
Custom Table widget not working.
Update facet display names in the data ingestion logs tab of the Monitoring project.
Numeric values extracted as strings by
Filebeatfrom the log files and stored as such.Additional dashboard and widget queries not added to the reference documents search inside Document Details.
Backend not returning
show_in_cardsfield for the types andiconfor the subtypes in Reference Screen.Remove empty data directories from the
inputstreamwhen using theQueueFileSystemStreamercontent streamer.Crawler issue when the website has no title.
Respect the
MAX_FILESsetting in the file upload control for the Data Loader plugin.Fixed the duplicated Crawler entry in the Web tab and removed redundant entries for the Dropbox and Google Drive connectors from the Enterprise tab.
The streaming chat endpoint now overwrites the payload tokens with the query parameter tokens when both are provided.
Removed a misleading warning log message from
FileSystemStreamer.get_number_of_batcheslogged insideingester.log.Fixed issues with dynamic template overwriting during migrations, ensuring proper appending.
Resolved highlighting issues in items using the
FuzzyMatchplugin in thein_ordermode.Fixed 403 errors occurring on websites with empty
Authorizationheaders.Collections filter now compatible with the semantic search.
Resolved issues causing balanced AutoML templates to fail during model training.
Ensured project deletions clear out project-specific caches as expected.
Removed epoch hyperparameter from the AutoGluon classifier due to its deprecation, allowing automatic adjustment of epochs instead of having a fixated value.
Corrected Redis instance usage by QFSS for Ansible deployments, to use
redis-serverinstead ofredis-server-cache.Update to prevent potential exposure of OpenAI keys.
Assistant settings not correctly saved.
Frequent inactive custom tool calling for Llama models.
Frequent inactive custom tool calling for models hosted by Cerebras.
Source match intent detector not respecting the sqgpt configurations.
Diverse padding for item detail content outside of PDF mode.
Favorite Filters cleared after applying advanced search.
After saving a favorite filter from Global Search, dashboard filters not cleared
Default API key in the SquirroGPT settings sometimes improperly handled.
Sharing a Community360 dashboard URL does not filter by the selected community.
Improved sqgpt service configuration to support generic GenAI client.
Internal GenAI client not using the sqgpt configuration.
GenAI not working with Azure OpenAI deployments.
Squirro Retriever fails to correctly handle the rewritten query coming from query-processing triggered via Global Search.
Assistant settings not being saved correctly.
ActionWidget buttons show escaped labels.
Context length incorrectly parsed for the Llama and Gemini models.
Fixed an issue where setting no context_length errored out the Llama model.
Ignore
frontend.userapp.languagewhich is not part offrontend.userapp.languages.Pipeline actions menu appearing behind the properties panel.
When no communities to show in All mode, the tabs are hidden.
Removed navbar actions in password reset mode.
Dashboard Share functionality whenever the Chat widget is present on the dashboard or not.
Facets dropdown sometimes not updating to the disabled state when it has no values.
Drop deprecated query argument for Squirro lookup (merge auxiliary query with query_context).
Duplicated dashboard query in typeahead filter query (GlobalSearch).
Llama model error due to the “n” extra parameter.
Fixed Data Virtualization integration breaking the
genaiservice when using Gemini or other non-OpenAI models.Fix the password reset flow.
The
redis_passwordof thequeues_rerun_from_indexconfiguration option of/etc/squirro/datasource.iniwill now get encrypted by the encrypt config files tool.Accurately reflect the current Global Search scope in the global search bar.
Use the active item ID for modal URL creation on copy item URL.
Support changing active reference item from the similar items panel.
Character added to the final query twice when a query in the Search widget ends with a special character.
Use the source ID for the bar chart source selection.
Concept search chip is not shown in the global search.
Fix width of entities dropdown buttons.
Once a collection is deleted, remove it from dashboard selection.
Properly combine
dashboard-selectio``nstate with follow upchat-question.Fix throw in chat widget when opened in dashboard without Global Search.
In some cases a Global Search query is cleared after switching from another dashboard to the global search.
Items skipped during the PDF OCR step will no longer be marked as failed and will proceed normally to the next pipeline step.
Fixing
chat-with-search-results,chat-with-selection,chat-with-favoritesandchat-with-collectionfor both legacy and new retriever.Project image used in project selector instead of company logo.
Increase
fastcgi_buffer_sizefor Studio plugins to 16kB to enable the creation of data sources using the Confluence 1-click connector.Dashboard query missing logical operators in typeahead filter query (SearchWidget).
Layer name dynamically updated when changed using the dashboard editor.
Miscellaneous#
Removed SquirroGPT - Mixtral project template.
Maximum number of retries for an item in a pipeline workflow reduced from 10 to 3.
Default Elasticsearch highlighter type switched to unified from plain to ensure support of knn-query and post-filtering with Elastic 8.16.
Elasticsearch upgraded to version 8.16.0.
Known issues#
LLMs hosted by Google AI may sometimes bypass the tool calling step, causing agent workflows issues (SQ-25865).
Labels technical names with spaces cause backend issues and errors (SQ-26080).
Breaking Changes#
The default value for retriever in the SquirroGPT configuration is now squirro_retriever, as vectorsearch_retriever is no longer supported. The Squirro instances using vectorsearch_retriever must change this value at the project or server-level configuration.
The
FileSystemStreamer.get_number_of_batches_per_projectand FileSystemStreamer.get_number_of_batches_per_source methods have been removed. The FileSystemStreamer.get_number_of_batches method, in combination with the entity_type and entity_id parameters, now serves the same purpose. The entity_type parameter specifies whether the entity_id should be treated as a project or source ID.API changes for the
FileSystemStreamer.get_number_of_batchespublic method: thedata_dirname_patternparameter was removed, as the method now defaults to counting the number of batches for data directories. To count the number of failed batches, the newly addedonly_failedparameter must be used. Finally, the method now takes anentity_idparameter and constructs a pattern based on it.The Paragraph Embedding pipeline step, requires now a position associated with the text chunks to compute embeddings. This should be considered as a breaking change only if a custom step is used to perform text chunking. If the built-in Text Chunking step is used, no action is required.
The GenAI service RPM is now a weak dependency of the
clusternodeservice RPM for RHEL 8. It means thatsquirro.service.genaishould be installed by the package managers by default. An installation failure does not affect thesquirro-cluster-nodeinstallation. You can turn off the installation using theinstall_weak_deps=Falseflag fordnforyum. You can uninstall thesquirro.service.genaipackage without uninstallingsquirro-cluster-nodeas well, a typical approach for deployments wheresquirro.service.genaiis not running on the same system assquirro-cluster-node.top_k_aggregationdoes not work if you do not explicitly specifycommunitiesin the fields.Reverted
gunicornintroduction fortopicandfrontendservices due to unstable behaviors.The GenAI service RPM is now a weak dependency of the
clusternodeservice RPM for RHEL 8. By default, package managers should installsquirro.service.genai, but installation failures will not affect tehsquirro-cluster-nodeinstallation. Useinstall_weak_deps=Falsefordnforyumto turn off the installation. Thesquirro.service.genaipackage can be independently uninstalled without affectingsquirro-cluster-nodeto support deployments where they run on different machines.The
top_k_aggregationfunction now requires explicit specifyingcommunitiesinfields.When calling the search API, using the query and query_context parameters in a single query is no longer supported and results in a 400 error.
The Dashboard Read Only token has to be regenerated (Dashboard Token (read-only)) via Account/API Access.
Installation and Upgrade#
For new installations, find step-by-step instructions on the Install and Manage Squirro with Ansible page (recommended) and Installing Squirro on Linux pages.
To upgrade an existing installation, see the Upgrading Squirro page.