3.8.6 LTS Release Notes#
Warning
End of Life Release
Squirro 3.8.6 LTS reached end of life in October 2025 and is no longer supported. This release no longer receives security updates or bug fixes.
For the current supported LTS release and upgrade instructions, see Release Notes.
Squirro 3.8.6 LTS was released October 16, 2023.
Note
On November 03, 2023 a patch was released for Squirro 3.8.6 LTS. For details, see the 3.8.7 LTS Release Notes.
Reference: Learn more about the Squirro Release Process.
Caution
This release includes several breaking changes. See the Breaking Changes section at the end of this page to learn more.
What’s New#
Squirro 3.8.6 LTS includes significant platform improvements, including the following:
A redesigned and improved AI Studio.
New search features, including new scoring profiles, query syntax features, and the introduction of semantic Hybrid search.
Several Cognitive Search user interface improvements.
A new Documents connector for uploading local files to Squirro, replacing the ZIP connector.
Built-in forms functionality for Project Settings configuration options.
Many more general platform improvements!
SquirroGPT#
Although not part of this specific release, Squirro also introduced several major new SquirroGPT features and improvements over the past few months.
Reference: To learn more about Squirro’s generative AI offering, see Squirro Chat.
Redesigned and Improved AI Studio#
AI Studio has been completely reworked, with a redesigned UI, new features, and improved performance. Creating no-code machine learning models has never been easier. You can now create, train, and deploy models in three steps.

New or improved features include:
The introduction of AutoML templates (Fast, Balanced, and Accurate), which will train multiple models with automated hyperparameter tuning, model ensemble, and automatically deliver the best-performing model for the dataset.
AutoML-supported libraries, models, and algorithms include LightGBM, CatBoost, XGBoost, Fasttext, RandomForest, ExtraTrees, KNeighbour, NeuralNetTorch and FastText.
Proximity-rule-based bulk labeling for sentence-level classification models.
Query-based bulk labeling for document-level classification models. This enables importing training data into the ground truth using Squirro Item labels. Additionally, for more advanced users, this feature enables the creation of training data utilizing the full potential of Squirro’s Query Syntax.
Unpublish models from the publish screen, which will delete the published workflow from a Squirro project.
Added label selection during deploy of a model within AI Studio.
Added support for custom templates in AI Studio and improved template handling generally.
Deploy or undeploy a published model directly into/from a pipeline from the AI Studio, without having to open the Pipeline Editor. This will automatically place (or remove) the model as a pipelet within the classification step of a selected Squirro pipeline.
A completely redesigned and improved interface, as shown in the example screenshot below:

Technical improvements to AI Studio in this release include the following:
Labeling focus mode has been reworked and now delivers faster results.
Added a help dropdown for AI Studio pages.
Added an option to limit bulk labeling items.
Implemented document-level Bulk Labeling.
Added a more informative error message when trying to delete a ground truth that is being used by a model.
Reworked the sentences highlighting logic when fetching all groundtruth items to be the same as for an individual item (this fixed discrepancies for sentences).
Query labeling templates now accept a
query_countparameter to limit the number of items retrieved for bulk labeling.Added relationships from groundtruth to model and from model to publish in the machinelearning database.
ground_truth_namein model and publish will now automatically update with changes to theground_truth,model_namewill now automatically update with changes to the model. Also migrated allmachinelearningservice migrations to use the new Redis functionality to remember if it has been run before.Added the
include_pipeline_workflowsparameter togetrequests for published AI Studio models, which tells the ML service to retrieve thedatasourcepipeline workflows where the published models are being used.GETrequests to endpoints for getting data about published models now enrich each model with the pipeline workflows they are used in.There is a new integration endpoint for query-based bulk labeling.
Disabled balancing dataset on AutoML templates to avoid downsampling.
Reference: To learn more, see AI Studio.
A New Editable Explore Dashboard in the Setup Space#
The Explore dashboard in the Squirro Setup space is now editable thanks to the creation of a new Explore dashboard designation included with all new projects.

As part of this update, general Explore screen performance was improved, including the Items widget performance within the dashboard.
Reference: To learn more about this new dashboard designation, see the Explore Dashboard documentation.
New Search Scoring Profiles and Semantic Hybrid Search#
Squirro search has been improved and extended in this release, including the introduction of multiple new Scoring Profiles and the introduction of the semantic Hybrid search feature.
The following screenshot demonstrates its improved performance with natural language queries and its ability to highlight text that matches the query:

Note
Hybrid search is currently in beta. Its pipelet and semantic search components only work if a separate model is available, which is not the case for current Squirro out-of-the-box deployments.
New or improved search features include:
Introduced the beta feature Hybrid Search, which retrieves results based on semantic/vector processes and keywords. This feature was created by adding the scoring profile
semantic, allowing users to perform approximate vector searches on paragraph embeddings.Added the scoring profile
extractive-qa. This highlights the answer to a query within the top-ranked paragraphs.Added the scoring profile
cross-encoder. This allows for top-N paragraph reranking based on contextualized similarity ofquery and paragraph.The new Query Syntax feature
rank_by:{}:allows you to rank on optional scoring signals to boost matching documents without applying an overall filter. For example,guest wifi rank_by:{ source:faq }enforces matches onguest wifibut ranks documents higher that are tagged withsource:faq.The new Query Syntax feature
profile:{}:allows you to inject Scoring Profiles dynamically within the query syntax. For example, to filter items that have been read by the user in the last 10 days, the syntax isprofile:{ plugin:last_read $last_days:10 }. Another use case is to apply scoring profiles as additional ranking signals by combining the literalsrank_by&profile, for examplegenai how to rank_by:{ profile:{last_read} }. This matches documents with ``genai how to `` and further boosts last read items.Add new scoring-plugins for recommendations: on user-item-history (
recommend_on_user_items) & item id’s (recommend_on_item).Added Scoring Profiles: Boost, allowing you to boost documents that belong to the user’s subscribed communities. The plugin is usable within the query syntax via
profile:{plugin:subscribed_communities}. Boosting was previously known asrank_by.A new Scoring Profile plugin was created to recommend items based on users’ past searches. Use the profile within a query like profile:
{ plugin:recommend_on_searches $last_searches:5 }; This will return concept search results on the last five unique user queries. Related matching terms used for the recommendations are marked in bold and red.Search Scoring Profiles: Implemented
with_user_readprofile to tagreaditems before returning them via thequeryAPI.Added new Squirro Syntax, which allows proximity search using Span Near ES queries. An example of such syntax is
"auction of gas"~(3)which searches for documents where the terms inside quotes occur within 3 words in any order and"auction of gas"[3]which is similar, but only considers documents where the items occur in the order provided.Contextualized PDF Inline Search: An additional widget query template can now evaluate the parsed query context (to activate semantic search vs keyword search).
Squirro query syntax now supports multiple sort clauses, allowing you to add additional sorting clauses when two or more items match their primary sort criteria. See Multiple Sorting Criteria to learn more.
Squirro Docs now includes auto-generated Scoring Profile Plugin Reference documentation.
Reference: For more information on semantic and Hybrid search, see Semantic and Hybrid Search.
Cognitive Search User Interface Improvements#
Cognitive search has undergone a number of UI and UX improvements in this release. This includes a fresh new look and feel when searching, as well as a number of new features and improvements, including the ability to choose document highlighting color.

Also, document labels can now be viewed in a popover by clicking the label icon in the Items widget, allowing you to browse labels without leaving the search results page, as shown in the example image below:
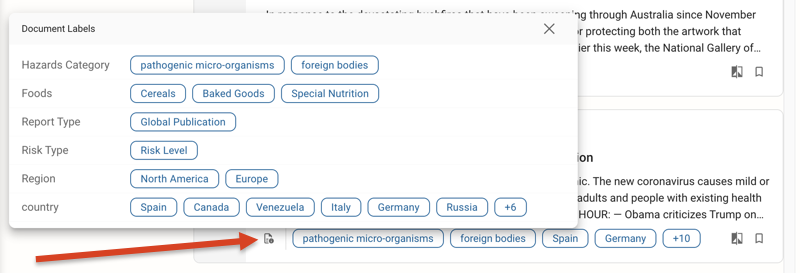
Other new Cognitive Search features and improvements include:
Global search now breaks queries into individual chips, making it easier to edit queries after the initial search. Through
frontend.userapp.query-chips-enabledin Project Settings this feature can be enabled or disabled. Learn more about Search Bar Chips.You can now configure the text highlight color via the Setup space App & Nav Bar Settings.
Upgrades to the Google Drive, SharePoint, and Dropbox 1-click connectors, including the input label, placeholder, and helper text.
Data sources now have an affiliated picture. They are initialized with the picture from the Dataloader plugin they are created from.
There is now support for loading images (TIFF, PNG, JPEG) into Squirro as PDFs.
Squirro now supports deploying a model to multiple pipelines at once.
Large PDFs are auto-scaled down to the viewer size.
Enabled typeahead for PDF inline search inside the Item Detail modal.
PDF inline search, which appears within the item detail screen, now uses the same query processing as global search. This significantly improves search quality inside the item detail screen and allows for future improvements on the backend.
Squirro now supports Speech to Text for the global search bar within Chrome browsers.
Added a Similar Items tab to the Items Detail widget.
The Items widget now has a configuration to specify which labels are shown when creating a new note using the Note Taking feature.
Added the Community Info Card widget to the platform.
A New Documents Connector#
A new Documents connector replaces the ZIP connector. In addition to handling ZIP files, this connector supports uploading individual, non-zipped documents (a single PDF file, for example). The range of supported documents was also expanded, including ODT, ODP, ODS, CSV, and RTF file formats.

Built-In Forms for Configuration Options#
Under Project Settings, intuitive built-in forms are now available for editing some configuration settings instead of plain text JSON. See the example topic.typeahead.content.configuration settings screenshot below:

Other New Platform Features and Major Improvements#
A new sessions mode with two default timeouts, session timeout and maximum session duration. Learn more at Reducing Session Lifetime.
A new and improved Squirro Monitoring dashboard. To learn more about manually upgrading an existing project dashboard, see Upgrading Dashboards Manually. (New Squirro releases update widgets automatically. Dashboards must be manually updated.)
Studio plugins using project-scoped endpoints now support token-based authentications. Token-based authentication is not supported for non-project-scoped endpoints for security reasons.
Added a new endpoint to expose SharePoint metadata in the SAML SSO Plugin.
Exposed priority levels in
squirro_data_load.Added a new libNLP step that truncates the fields of the given documents down to the first
Xwords.Storybook was updated to the latest version, add full widgets to storybook and community list widget tests
The
plumberservice can now emit structured logs. Structured logs generated during data ingestion (e.g. from the execution of a pipelet in a pipeline workflow) can now be included in the Data Ingestion Logs dashboard of the Squirro Monitoring project. Authors of pipelets can use the new attributeself.slogto emit structured logs from within their pipelets.Added the
indexmanagerservice.Admins can now access query-processing results in dashboard query templates using the
queryContextvariable.There is a new tag for highlighting answer context.
Introduced a new pipeline step called Archive Extraction that extracts archive files. At the moment only ZIP files are supported. Each file in the archive becomes an individual item, and the archive itself is removed.
Created a new index manager service for Elasticsearch maintenance.
Introduced a new pipeline step called MIME Type Detection that identifies the MIME type of file-based items. This step can serve as a central way to detect MIME types in the pipeline, instead of replicating this logic in various dataloader plugins in cases where the MIME type is either not provided or is not trusted because it may be incorrect.
Created the option to display only unique items within the Timeline and Metric widgets.
Included XlsxWriter as an optional package on the Squirro mirror.
Added GlobalSearch query to EntitiesListWidget query.
Now users can use
searchbar.emptyandsearchbar.valuein dashboard query templates.Added a new type of content streamer called QueueFileSystemStreamer. This streamer extends the existing FileSystemStreamer with the idea that each data source has its own distinct queue. It can be enabled by modifying the
/etc/squirro/common.inifile, by setting thestream_typeoption of the content section tofilesystem-queuefrom filesystem.Added documentation for the content streamers of the data processing pipeline. See Content Streamers.
Added an autogluon classifier to the libNLP classification steps.
You can now store metadata information on sub-items (pages) in the same way you can for top-level items. This metadata information can be used for internal operations and is not exposed via the Facet Aggregation API, which only considers top-level items.
Improvements#
Note
Bug fixes are included with individual biweekly non-LTS releases. If you are looking for bug fix information, see specific Squirro 3.8.x Release Notes.
The following general platform improvements are included with this LTS release:
Dashboards and Widgets#
The Items Table widget was migrated to React.
Show more than X number of results in Items widget when approximation is used on the backend.
General Items card improvements.
Items card in ItemsWidget now has a larger font and there is answer context highlighting in the abstract.
Global Search and Community 360 dashboards are no longer loaded on top of other dashboards.
Changed the default font size for the Chip component to 13px.
Changed yellow highlighting to bold font for highlighting inside item preview, item detail sidebar and HTML-based items. Yellow highlighting will still be used in the PDF highlighting.
Improved Tabs performance.
Updated default colors and themes based on the latest Cognitive Search design.
Users scroll to the first highlighted section within a document after clicking on a QA widget answer.
Added translate and compare tooltips to the ItemsWidget card.
Data Loading and Processing#
The three cloud connectors (Dropbox, Google Drive, OneDrive) now support zip files.
Added support for zip files in the Microsoft Exchange plugin.
The data sources in the Setup space now have a tooltip on their names in case their display name is clipped.
Ensured all connections have a 20-second timeout, including the
/_internal/statusendpoint.Enabled placeholders in
dataloaderinputs.Added an integration test for the synchronous batch processing feature.
Improvements to the Data Ingestion Logs dashboard in the Squirro Monitoring project. Specifically, batch-level start/end logs have been added for the pipeline steps operating in parallel execution mode. All batch-level start/end logs are now logged at the
infologging level, while all item-level start/end logs (which provide more detail, supported for steps with parallel execution mode) are logged at thedebuglogging level. Therefore, from now on, start/end logs will be displayed by default in the dashboard without the need to modify the logging level todebug. Finally, structured logs have been added in a few places to assist with understanding.The
pdfconversionservice can now emit structured logs, which are linked to the rest of the data ingestion logs. Therefore, structured logs from thepdfconversionservice will now be included in the Data Ingestion Logs dashboard of the Squirro Monitoring project.Increased and synchronized the timeout options related to pipelets involved in data ingestion.
The default pipeline workflows for Dropbox, Google Drive, and Microsoft OneDrive connectors now include the pdf-conversion and webshot steps. This means that MS Office documents found in these services will be converted to PDFs and a thumbnail will be created for them.
Improved the reliability of PDF conversions when multiple conversions take place in parallel.
Communities#
The CommunityItems widget was ported to React and a custom widget API was implemented.
Added feedback to the Communities List widget.
Community augmentation is now easier to implement by making all the returned fields optional. Name, photo, and properties are now used if present but don’t have to be returned.
Photos returned by community augmentation can now be absolute URLs as well.
Squirro now includes community types in the response after subscribing to a community.
Community subscriptions now reflect the state of applied filters and the search bar query.
Now the horizontal mode is available without relevant communities in the Communities List widget.
Added a widget query to the Communities List widget.
Added
queryto community subscriptions collection, allowing for community subscription filtering via query. This is currently available in the Items Table widget.
Search#
Simplified usage of scoring profiles. Plugins can now be more easily used and configured directly by their name as
profile:{ last_read count:10 }(This example boosts the last 10 read items).Within search, for better statistics on the indexed data, page offsets are now stored on PDF sub-items as numbers.
Added support to leverage multiple search scoring profiles at the execution stage (
rerank,render).Paragraphs are now stored in a separate Elasticsearch index.
Squirro now applies ACL queries as Elasticsearch filters. It allows Elasticsearch to cache the filters, thus users with the same ACLs will get results faster.
Added support for the
NOTliteral for search scoring profiles.Exposed search tuning parameters to the project configuration. This allows users to config additional Elasticsearch query API performance parameters.
Squirro now uses Orjson for Elasticsearch serialization and deserialization. This improves performance as Orjson is much faster than the simple JSON used by the Elasticsearch client.
Now, Orjson is used for the SquirroClient. It improves the performance of serializing and deserializing data. It is also used in the WebOb package to improve the speed of parsing responses.
When searching, improved the retrieval of relevant documents and highlighting of matching tokens (including lemmas & stems) based on the detected language of the provided query. The language distribution across indexed documents is considered to achieve stable language detection for short keyword queries.
Search indexing now uses the recommended (more aggressive) stemmers for all supported languages.
Removed typeahead suggestions that don’t include meaningful content, a standalone asterisk symbol (*) for example.
Returned scoring profile items are now tagged with associated/relevant scoring-profiles (= profiles that matched on the item and boosted its relevancy score). See
item.matched_profiles.Added an option to specify
samplerfor search aggregations. It can be used within instances with a large number of documents to drastically improve performance.Added an option to quantize embeddings. This allows for storing embeddings as bytes in the Elasticsearch index.
Now, when a phrase or proximity filter is applied to the query, the whole phrase is highlighted, not individual terms.
Squirro now returns the number of sampled documents by Elasticsearch. This allows the UI to display how many documents were sampled when using the random or aggregation sampler.
Within the typeahead API, suggestions may contain the new field
chipsif requested (options.with_tokenized_suggestion:bool). These additionalchiptokens are used to render the chips in the global search bar.Introduced a new highlighting tag for quick answers, with key answer terms bolded.
Phrases are now highlighted in a more robust way (don’t split tokens).
Enriched session with query-context metadata like user terms and filters, detected query language, noun chunks, and named entities.
Stopwords are no longer highlighted in abstracts. Highlights are stripped from Elasticsearch and the abstract is highlighted by Squirro based on “cleaned” terms.
Other Improvements#
Now,
squirro_statusworks even if a service is not installed.Suppressed the
Instantiate SkipTimeoutConnectionClassmessage insquirro_statusoutput.Reduced noisy logging in
frontend.logby the monitoring plugin.Store read item IDs on the frontend to show the correct status immediately to the user.
Enabled
http2for all resources.Various extensions and improvements to the structured logging system.
File-based Squirro items (i.e. items that include the
filesattribute) returned by the API will now include anoriginal: trueflag to indicate the file from which the item is derived.Updates to 1-Click Connector configuration forms.
Moved the
nlp serviceconfig to the configuration service so that the config is displayed in a user-friendly way.Added config to enable/disable balancing of dataset inside balancer step.
Activity Insights now has higher scheduling frequency and separate backoff time for long-lived sessions with 15min (dashboard & browsing session) and short-lived query session (3 minutes).
Added validation to the configuration service. Now, dictionary settings defined in the configuration service may include a schema definition that is then used for validation, e.g. provided text instead of number, value not within specified range etc.
Upgraded Filebeat to version 8.8.1.
Limited the number of
max_featuresused on SKLearn transformer to avoid too much memory consumption when a dataset is too large.
Breaking Changes#
See the following three categories for breaking changes included with Squirro 3.8.6 LTS:
General#
The Items widget was redesigned. While the API remains the same, verify that any customizations you’ve made within your projects still work correctly.
Result List and Cards widgets have been removed from the UI. Both are still supported if they already exist within a project, though they are slated for full depreciation during the next LTS release.
The public methods
enqueueandenqueue_dataof theFileSystemStreamerwill now return the absolute path to the enqueued data file.The plumber service can no longer be forked as forking was causing degraded service performance.
In the App and Nav Bar Settings, project colors now support only the HEX color schema. Admins should update project colors accordingly.
AI Studio#
Dropped the
ground_truth_namecolumn in themodelstable.Deprecated the ability to change the
idandnameof the groundtruth in themodelstable.Dropped the
gt_id,gt_name, andmodel_namecolumns in thepublishtable.Adding a document-level classification model to a pipeline now requires the
document_labelargument that defines the label category used for the model to output its predictions.If you are using custom templates within AI Studio, they must be handled using the new structure.
Search#
The Smart Filters feature is now fully deprecated.
The
perform_on_languagesoption in the QA widget configuration no longer supports theNonevalue. To find an answer regardless of the language of the question, set this option to*.The
terminate_afteroption in the content typeahead configuration no longer supports boolean values. To stop query execution from terminating early, set this option to0.Changed the default value of
track_total_hitsfromtrueto 500,000 to optimize query performance. This means that Elasticsearch will now stop counting documents when the value exceeds this threshold. To change this behavior, see thetrack_total_hitsoption in thetopic.search.search-settingsconfiguration service option.
Note
For help with breaking changes, contact Squirro Support.
Installation and Upgrade#
For new installations, find step-by-step instructions in Install and Manage Squirro with Ansible (recommended) or Installing Squirro on Linux.
To upgrade an existing installation, see Upgrading Squirro.