Query Processing#
Profile: Search Engineer
This page provides an overview of query-processing workflows in the Squirro platform.
Query-processing workflows are modified by search engineers to fine-tune the search experience for users.
Overview#
Query processing improves a user’s search experience by providing more relevant search results.
Squirro achieves this improvement by running each user query through a customizable query-processing workflow that parses, filters, enriches, and expands queries before performing the actual search and presenting the search results to the user.
Example: Part of speech (POS) boosting and filtering removes irrelevant terms like conjunctions from the query and gives more weight to relevant parts of the query, like nouns. The returned search results rank items that match boosted query terms higher.
Query-Processing Flow Diagram#
The figure below illustrates how query processing fits into Squirro’s overall architecture.
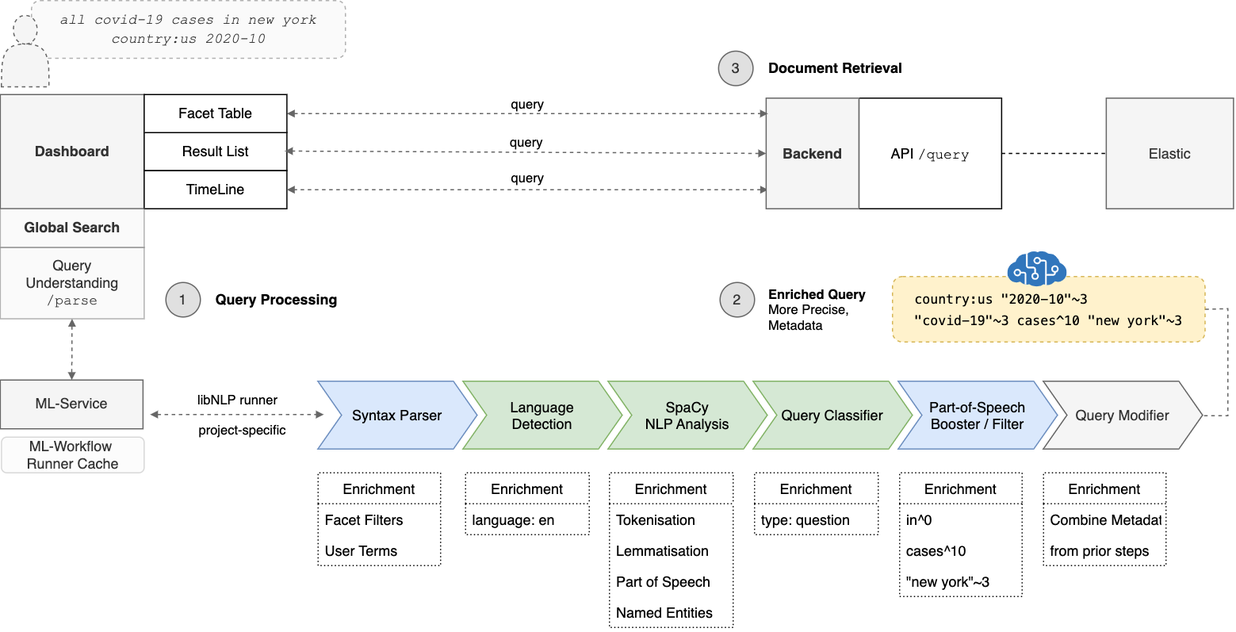
In the example above, the user enters the query country:us 2020-10 covid cases in new york in the global search bar.
Squirro then sends the query through the Query Understanding Plugin (1) to the ML-Service where the query-processing workflow (a Squirro ML-Workflow) executes and applies the following steps on the incoming query:
Language detection.
Languag-specific spaCy analysis. This uses the pre-trained spaCy language model (see example) for the detected language. The analysis includes:
Tokenization and lemmatization
POS tagging
Named Entity Recognition (NER)
POS booster and filer.
Query modifier. The final query modifier step applies all modifications to the initial query to produce the Enriched Query (2) which is then used to retrieve the candidate documents that best match the query from the Elasticsearch index (3).
Query processing and rewriting improve the search experience by ranking items that match boosted terms higher and reducing the appearance of irrelevant search results for the query. It achieves this by combining terms that belong together. Entities like “New York “will be treated as such in the query, preventing multipage items (e.g., PDFs) that have “new” on one page and “york” on a different page from being matched and appearing in the search results.
Configuration#
Each project is pre-configured with a default query processing workflow. The workflow is installed on the server as a global asset and cannot be deleted via the user interface.
The query-processing workflow is enabled by default.
You can manage the behavior of the workflow in the project configuration under the Settings tab.
Name |
Value |
Description |
|---|---|---|
|
|
Disable query processing. |
|
|
Enable query processing. |
|
${ |
Set the value to the |
|
|
Execute workflow for every request to the |
|
|
Execute query processing workflow once for the whole dashboard (triggered via Global Search Bar widget). |
Workflow Management#
Configuring Available Workflows#
You can configure the available workflows under AI Studio > ML Workflows.
Every project has a default query-processing workflow by default. This default workflow is read-only and cannot be deleted or modified. The Machine-Learning (ML) Service manages this and automatically updates it to the latest version.
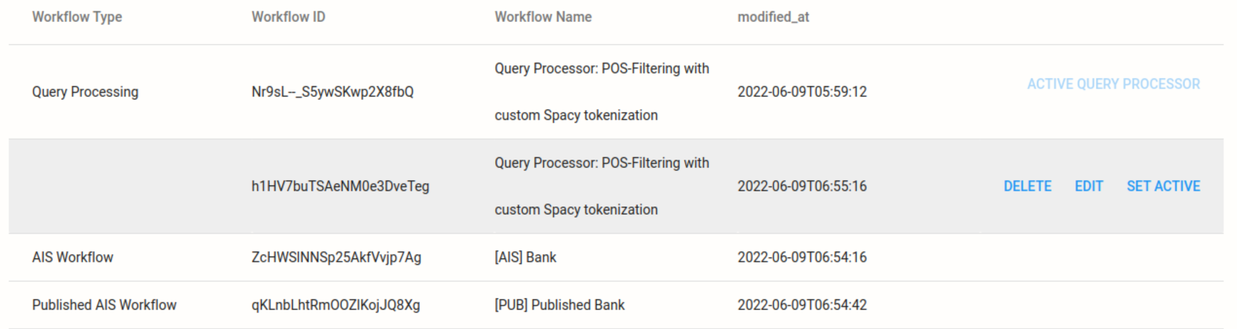
The default query-processing workflow is set as the Active Query Processor and is listed along with any other custom workflow, as shown in the screen capture below:

If you want to customize the behavior of the default query-processing workflow, perform the following steps:
Caution: Following these steps will make the workflow you select the active query processor.
Clone the workflow.
Edit its configuration.
Hover over the newly-created workflow and click Set Active.
The screen capture below shows how Set Active becomes visible on hover:
Disabling the Default Query-Processing Workflow#
The default query processing workflow cannot be deleted, but can be disabled. To disable query processing, perform the following:
Navigate to Settings > Project Configuration.
Change the
topic.search.query-workflow-enabledoption by clicking Edit.Uncheck the checkbox.
Query-Processing Workflow Steps#
For information on creating custom query-processing workflow steps, see How to Create Custom Query-Processing Steps.
The default query-processing workflow uses the following built-in libNLP app.query_processing steps:
Reference: Pre-configured Query Processing Pipeline Steps
1{
2 "cacheable": true,
3 "dataset": {
4 "items": []
5 },
6 "pipeline": [
7 {
8 "fields": ["query"],
9 "step": "loader",
10 "type": "squirro_item"
11 },
12 {
13 "step": "app",
14 "type": "query_processing",
15 "name": "syntax_parser"
16 },
17 {
18 "step": "app",
19 "type": "query_processing",
20 "name": "lang_detection",
21 "fallback_language": "en"
22 },
23 {
24 "step": "flow",
25 "type": "condition",
26 "condition": {
27 "healthy_nlp_service": {
28 "service": "spacy",
29 "language": "*",
30 "worker": "*"
31 }
32 },
33 "true_step": {
34 "step": "external",
35 "type": "remote_spacy",
36 "name": "remote_spacy",
37 "field_mapping": {
38 "user_terms_str": "nlp"
39 },
40 "disable_pipes__default": ["merge_noun_chunks"]
41 },
42 "false_step": {
43 "step": "app",
44 "type": "query_processing",
45 "name": "custom_spacy_normalizer",
46 "model_cache_expiration": 345600,
47 "infix_split_hyphen": false,
48 "infix_split_chars": ":<>=",
49 "merge_noun_chunks": false,
50 "merge_phrases": true,
51 "merge_entities": true,
52 "fallback_language": "en",
53 "exclude_spacy_pipes": [],
54 "spacy_model_mapping": {
55 "en": "en_core_web_sm",
56 "de": "de_core_news_sm"
57 }
58 }
59 },
60 {
61 "step": "app",
62 "type": "query_processing",
63 "name": "pos_booster",
64 "phrase_proximity_distance": 10,
65 "min_query_length": 2,
66 "pos_weight_map": {
67 "PROPN": "-",
68 "NOUN": "-",
69 "VERB": "-",
70 "ADV": "-",
71 "CCONJ": "-",
72 "ADP": "-",
73 "ADJ": "-",
74 "X": "-",
75 "NUM": "-",
76 "SYM": "-"
77 }
78 },
79 {
80 "step": "app",
81 "type": "query_processing",
82 "name": "lemma_tagger"
83 },
84 {
85 "step": "app",
86 "type": "query_processing",
87 "name": "query_classifier",
88 "model": "svm-query-classifier"
89 },
90 {
91 "date_match_on_facet": "item_created_at",
92 "date_match_rewrite_mode": "boost_query",
93 "label_lookup_match_ngram_field": true,
94 "label_lookup_fuzzy": true,
95 "label_lookup_prefix_queries": false,
96 "label_lookup_most_common_rescoring": true,
97 "label_match_category_weights": {
98 },
99 "label_lookup_rescore_parameters": {
100 },
101 "label_match_rewrite_mode": "boost_query",
102 "match_entity_phrase_slop": 1,
103 "name": "intent_detector",
104 "step": "app",
105 "type": "query_processing"
106 },
107 {
108 "step": "app",
109 "type": "query_processing",
110 "name": "query_modifier"
111 },
112 {
113 "step": "debugger",
114 "type": "log_fields",
115 "fields": [
116 "user_terms",
117 "facet_filters",
118 "pos_mutations",
119 "type",
120 "enriched_query",
121 "lemma_map"
122 ],
123 "log_level": "info"
124 }
125 ]
126}
The workflow is set to:
Parse Squirro query syntax and detect query Language based on available natural language terms.
Perform named entity recognition (NER).pip install –upgrade -r requirements.txt The entity compound is then rewritten into an additional phrase query.
Example:
cases in new york–> rewritten as –>cases in(new york OR "new york"~10)Boost important terms based on their POS tags. (For more information, see Universal POS tags).
Example: Boost nouns (tags
NOUNandPROPN) by assigning higher weights in thepos_weight_map.Example: Reduce the impact of verbs (
VERB) by assigning lower weights.Remove terms like determiners and conjunctions from the query.
Perform query classification:
question_or_statementvskeyword.
Reminder: You can configure the steps of the query-processing workflow in AI Studio.
Lemmatized Search#
To return better and more relevant search results, Squirro uses lemmatized search as a step within the default query-processing workflow.
Lemmatized search is an advanced alternative to stemming, which focuses on explicit word roots.
Lemmatized Search Explained#
Lemmatization aims to reduce multiple similar words to common root forms. As opposed to more basic reduction techniques, such as stemming, lemmatization considers more than the physical word itself.
Rather than removing prefixes and suffixes to identify a stem, lemmatization looks at the word itself combined with the context of the words around it to identify a lemma tied to a dictionary definition.
Example: If the words good and better appear in your documents, stemming or simple keyword matching won’t relate the two words. Lemmatization, however, would relate the two words because it would treat good as the lemma of better.
Pros versus Cons#
Generally speaking, lemmatization provides better, more relevant results than stemming or using simple keyword matching.
However, performing lemmatized search requires some additional query-processing time and resources.
Disabling Lemmatization#
For projects that do not require anything beyond straightforward keyword matching, or projects where minimizing processing time is a priority, you may want to consider disabling lemmatized search.
If you wish to disable lemmatized search, follow the steps below:
Log in to your Squirro project.
Navigate to Setup > AI Studio.
Click ML Workflows in the left menu.
Hover over your project’s active query processor and click Edit.
In the configuration code, locate the
exclude_spacy_pipessetting and add “lemmatizer”. (This prevents thenlp-analysisstep from computing lemmas.)
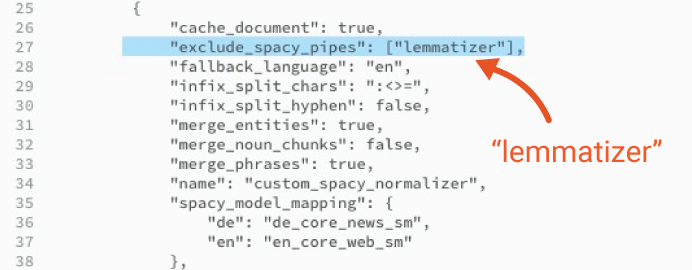
Delete the
lemma_taggerstep as shown in the image below:

Click Save.
Creating Custom Query-Processing Steps#
See How to Create Custom Query-Processing Steps for instructions on how to create custom query-processing steps.
How To Install a SpaCy Language Model#
You can install additional language models based upon available SpaCy Models.
To install Japanese, for example, you would run the following command:
python -m spacy download ja_core_news_sm