Document Relevancy#
Profiles: Project Creator, Search Engineer
This page explains Document Relevancy ranking within Squirro Cognitive Search.
If you’re looking for step-by-step guides to refine relevancy in different ways, see the following:
Search engineers can tune the relevancy ranking of documents in Squirro Cognitive Search and project creators can implement those changes in the Squirro UI.
Note
Optimizing each stage of the retrieval pipeline is crucial for achieving highly accurate search results.

Overview#
The baseline full-text search provides a good document relevancy score (BM25) out of the box.
But with different domains, users, and preferences, it’s important to consider the overall context and tune the search scoring to return the information that the user is truly looking for.
Personalization of search results
by promoting information from a specific datasource to certain users (e.g. department specific)
by promoting priorly updated or visited documents (e.g. last read item, popular among other users..)
Help non-expert users to find the relevant information, even if they do not know the actual technical domain language
by performing query expansion with domain specific synonyms
by finding semantically similar documents without the requirement of matching technical keywords
We differentiate two tuneable areas for relevancy tuning: data loading & query time
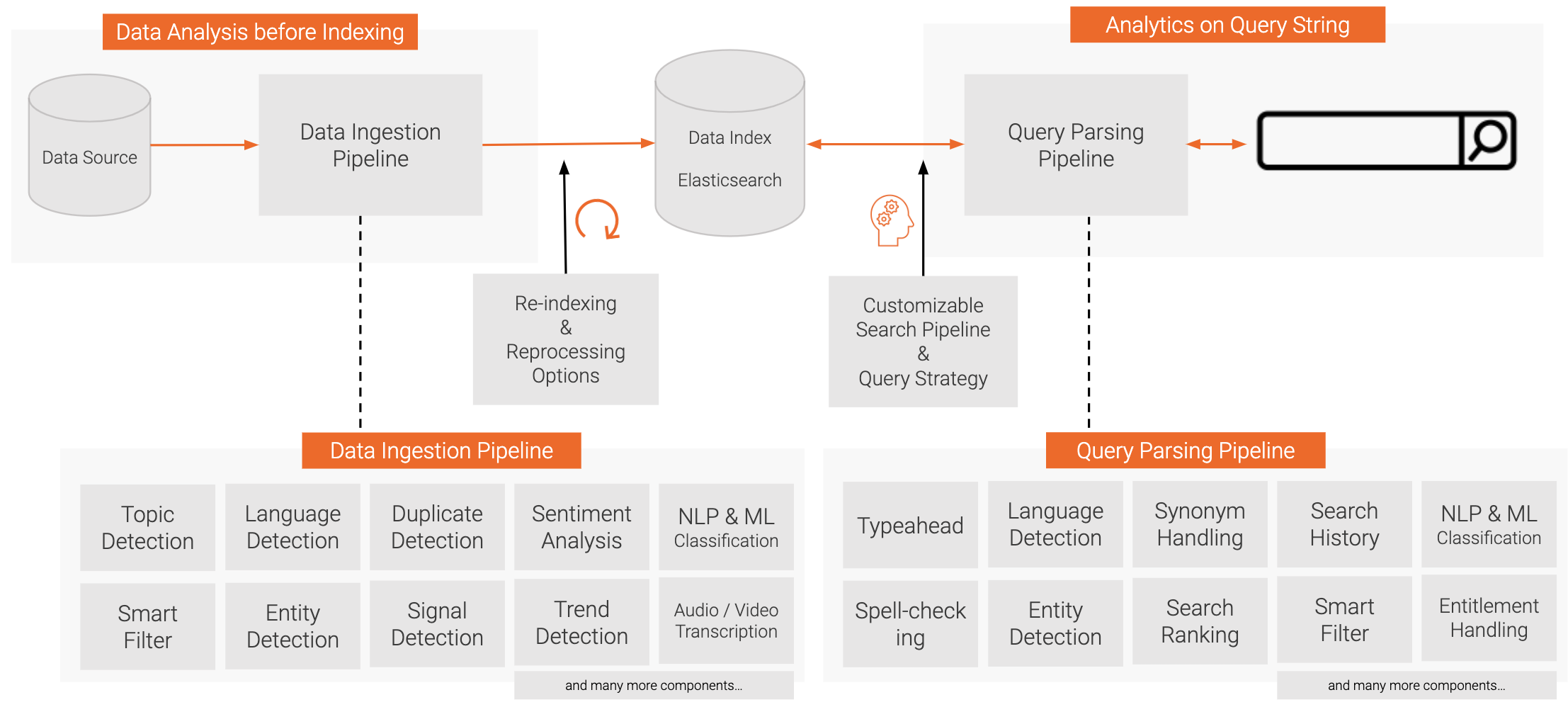
Relevance Tuning: Document Features#
Enrich documents with relevant metadata (labels) during data loading time. Those labels can then be used to impact document relevancy scoring.
Source systems may already maintain important metadata like
Who is the document author / contributor?
When was the document created? Any updates?
Is the document already classified into predefined categories / ontologies?
Is it an official, important FAQ document or an internal call note?
But usually a majority of relevant insights are hidden in unstructured text, e.g. big PDFs, and first needs to be uncovered. This can be done by adding additional enrichment components to the data loading pipeline.
AI Studio Model: Train & apply your own ML classifier, e.g to detect overall sentiment, or document category
Custom Pipelets : Write your own plugin to enrich documents while data loading
Scoring Profiles#
Document metadata can be used as additional ranking signals to return the most relevant documents on top.

For example, you might want to promote documents coming from a specific datasource - like internal FAQ material - over generic office documents.
This can be achieved by defining a Scoring Profile that promotes documents tagged with a Label source:faq.
See How to Use Scoring Profiles to Customize Document Relevancy Scoring
Scoring Plugins#
Scoring plugins are specific implementations of scoring profiles used to inject custom business logic.
Each plugin is configured with a set of parameters that can be used to customize the plugin’s behavior.
Tip
You can write and upload your own Scoring Plugins using the PluginProfile.
Reference: To learn more, see Scoring Plugins.
Searchable Labels#
Apply Full Text Search on additional textual metadata in order to refine the Text Match Relevancy Score.
Relevance Tuning: Query Enrichment#
Note
To analyze the query and understand what a user is actually looking for is as important as analyzing documents during data loading.
Query Understanding & Rewriting#
Cognitive Search offers a customizeable query processing workflow that parses, enriches, and expands queries before performing the actual search. The built-in features range from language detection, named entity recognition and semantic synonym expansion.
For more information see Query Processing.

Query Term Matching Strategy#
Tune document relevancy scoring by configuring how the user’s Search Query Terms are matched.
Example: Multi-Word Matching
When a user searches for a simple keyword query like global warming, it is expected that documents are ranked highest where both terms global and warming are found within very close proximity e.g. the same sentence. Documents that contain global on Page 1 but warming on Page 10 are not considered to be relevant.
Promote documents that match the query terms in close proximity. This can be done using a rescore function that applies loose phrase matching on the top N ranked documents (more expensive scoring applied only on top N to keep the response time low)
Changelog#
Squirro 3.6.1: Initial Release of Scoring Profiles