Project Creator#
Profile: Project Creator
The Project Creator role sits at the center of all Squirro projects.
This page provides information on the project creator role, a summary of role capabilities, and an overview of how the role fits within each stage of Squirro’s Gather → Understand → Act framework.
Introduction#
As a Squirro project creator, you can set up and configure individual projects and workflows. In addition to adjusting Squirro’s out-of-the-box features, you can customize workflow steps or plugins to extend Squirro’s functionality.
You’ll work closely with end users to understand project goals and collect feedback.
You may also work with data scientists and model creators to train machine learning models to gain deeper insights into connected data sources.
Working with python engineers and frontend developers, you can extend Squirro’s functionalities in many ways. From connecting new data sources to developing custom data enrichments and dashboard display widgets, there are few limits on expansion and customization possibilities.
Important: Remember that Squirro profiles are based on your specific job type. Some profile roles overlap, and some individuals may fill multiple roles on a project. Squirro profiles do not directly correlate with administrative permission levels.
Capabilities Quick Summary#
As a project creator, you can perform the following actions:
Connect any data source to Squirro. See Data Loading.
Create data labels to improve search relevancy. See Document Relevancy.
Create communities to group project data by topic. See the Communities Tutorial.
Perform AI Studio tasks such as classification and search tagging. See AI Studio.
Adjust visualizations through dashboard settings, custom widgets, and themes. See Dashboards.
Perform administrative tasks such as adding and removing project members, configuring basic project settings, and importing and exporting projects. See User Interface.
Prerequisites#
You’ll need Administrator access to your Squirro project to perform most project creator functions.
Your system administrator can set that permission level for you if you find that you only have read access to your project.
Reference: To learn more, see Squirro Roles & Permissions.
Role Overview#
Squirro operates under a Gather → Understand → Act framework. As the project creator, you are an essential part of each step in the process.
You also have the best overview of your project’s data pipeline, from data sources to enrichments to how your team visualizes information.
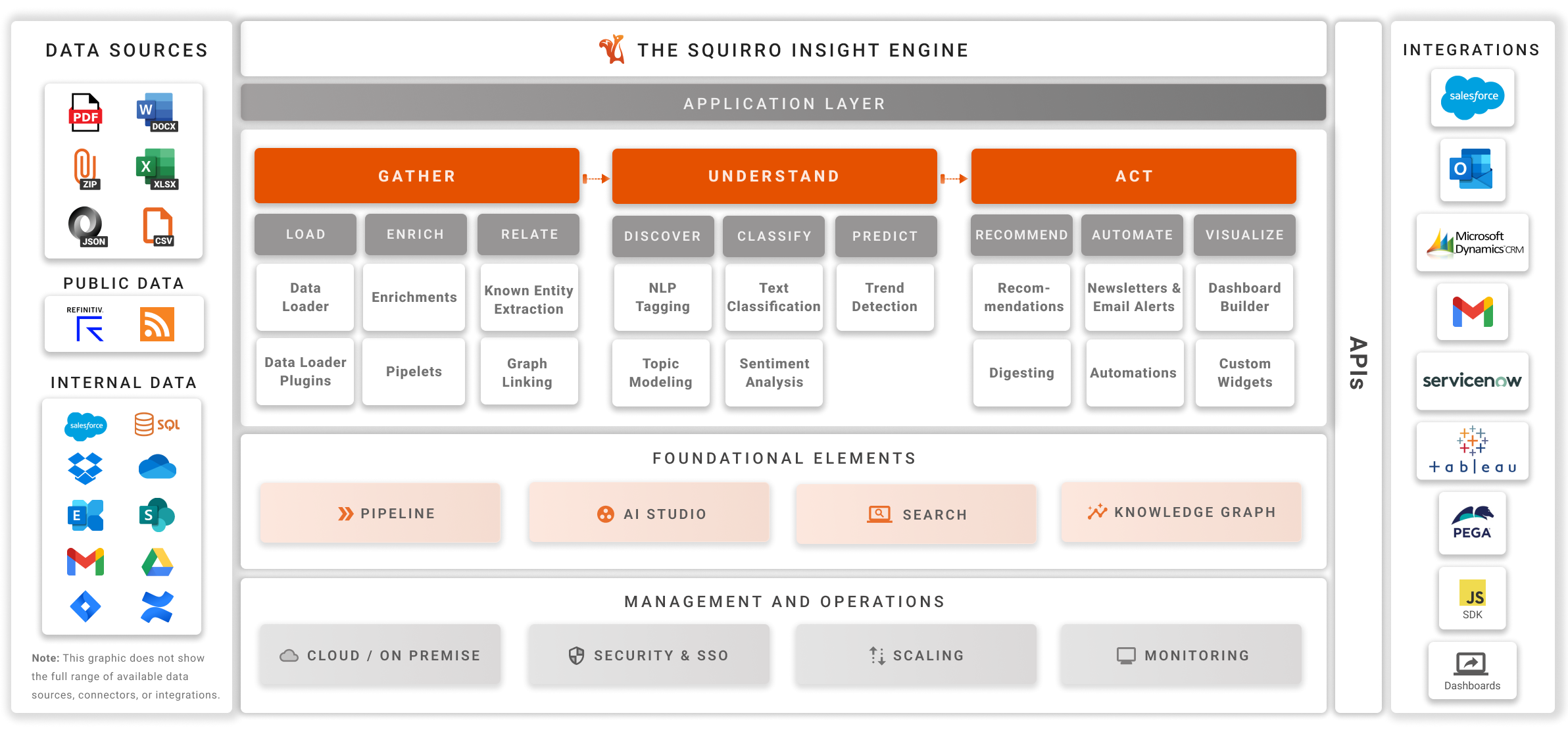
Gather#
Load#
The starting point of every good project is good data.
Squirro allows you to connect any type of structured or unstructured data to your project. The platform has built-in connectors for most data sources.
There are two ways to connect data sources to your project:
Through Setup -> Data -> Data Sources in your browser.
Using the Squirro Data Loader
Reference: Learn how to connect data:
Through your browser by reading about the UI Data Loader.
Using the Data Loader Command Line Tool by reading the Data Loader Command Line Interface Tool Tutorial.
Tip: If you have a data source that doesn’t work with standard connectors, you can resolve the issue by having a python engineer create a custom Data Loader Plugin. For more information, see How To Write a Custom Data Loader Plugin.
Enrich#
Enrichments are steps in the Squirro data pipeline that enhance items extracted from connected data sources.
Squirro comes with many out-of-the-box enrichment steps, including the following:
Unshorten Link
Duplicate Detection
Content Augmentation
PDF OCR
Noise Removal
Thumbnail Extraction
Language Detection
PDF Conversion
Content Extraction
Python engineers can also create custom enrichment steps by writing custom pipelets that you can add to the enrichment workflow. For more information, see Writing Pipelets.
Relate#
You can link unstructured data within connected data sources to structured data using Known Entity Extraction (KEE). For example, you can extract a list of company names from a CRM such as Salesforce and link that company information to unstructured documents such as emails, call notes, and news articles.
To learn more about KEE, see Known Entity Extraction.
KEE is a powerful feature that allows you to add structure to large volumes of otherwise unstructured data quickly. You can add KEE to your pipeline’s workflow in two ways:
Through AI Studio by following the KEE Studio Plugin Tutorial.
Through the command line by following the KEE CLI Tool Tutorial.
Understand#
Data scientists and model creators primarily lead this stage. However, as the project creator, you play an essential role as a facilitator and as the person configuring workflows within the project dashboard.
You can work with project team members to:
Configure the NLP Keyphrase Tagger to perform key-phrase extraction, named entity recognition, and rule-based sentiment analysis.
Create machine learning models and enrichments and incorporate them within workflows using the AI Data Studio.
Act#
With your data gathered and understood, there are many ways to create better search experiences for end users and generate actionable insights from project data.
Customizing search settings to fit team and project needs is one of the project creator’s most important roles. This includes configuring the following features:
Troubleshooting#
Q1: I’m having trouble accessing a particular project creator feature, what should I do?
Answer: Contact your project’s System Administrator. This person is responsible for assigning permissions within the platform. If they can’t resolve your issue, reach out to a Squirro Solutions Engineer for further assistance.