3.13.6 LTS Release Notes#
Squirro 3.13.6 was released on July 29, 2025.
Learn more about the Squirro Release Process. When upgrading between LTS releases, see the Upgrading Squirro page for important information about the sequential upgrade path.
Attention
Elasticsearch upgrade to version 9 - Before switching to the 3.13.6 LTS or the 3.13.5 release, ensure you prepare your infrastructure. Refer to the Elasticsearch Migration page for detailed instructions on migrating Elasticsearch indices.
3.13.6 build 59
Squirro released a patch for 3.13.6 LTS on December 19, 2025. To check your current build number, see Checking Build Numbers.
Critical security update addressing a vulnerability in a third-party dependency.
Administrators are strongly advised to update Squirro instances during the next maintenance window. The patch is deployed through the standard update mechanism and maintains full compatibility with the initial 3.13.6 LTS release.
3.13.6 build 58
Squirro released a patch for 3.13.6 LTS on August 28, 2025. To check your current build number, see Checking Build Numbers.
Fixed an issue where NER classifier-generated entities had inverted Y-coordinates when displayed on the Item Detail widget.
Fixed an error related to the creation of a RheinInsights data connector.
(Workspaces instances only) Fixed screen flickering issue for users with Reader role and another one related to managing project members.
Fixed issue with quotes handling in search plugin arguments.
The patch is deployed through the standard update mechanism and maintains full compatibility with the initial 3.13.6 LTS release.
3.13.6 build 55
Squirro released a patch for 3.13.6 LTS on August 8, 2025. To check your current build number, see Checking Build Numbers.
Fixed an issue where classifier-related table creation failed in PostgreSQL due to duplicate
UniqueConstraintnames.Fixed an issue where the SharePoint connector failed to load data due to the dataloader looking for
mappings.jsonin the wrong directory path.
The patch is deployed through the standard update mechanism and maintains full compatibility with the initial 3.13.6 LTS release.
Notes for administrators
Squirro Classifier and the agent configuration using the web interface are still in development. If you have suggestions for improvement, visit the Squirro Support website and submit a feedback request.
A recent fix addressed an issue where an incorrect prompt was added to paragraphs-to-be-embedded and will cause new ingested embeddings to differ slightly from prior embeddings. After migrating to 3.13.6, if you notice a significant impact on retrieval quality, a re-embedding of the paragraphs may be necessary to improve accuracy. For assistance, visit the Squirro Support website and open a technical support request.
This release introduces important changes that may require adjustments to your existing setup. Learn more
Note for developers
To maintain compatibility with the recent dashboard selections rewrite, custom widgets in the Squirro platform require updates. Frontend developers should plan to replace deprecated methods and update widget code to align with the new architecture. For assistance, contact Squirro Support and open a technical support request to receive guidance from experts.
What’s New#
Squirro Classifier for entity detection, entity linking capabilities, and integration with taxonomies from Synaptica. Learn more
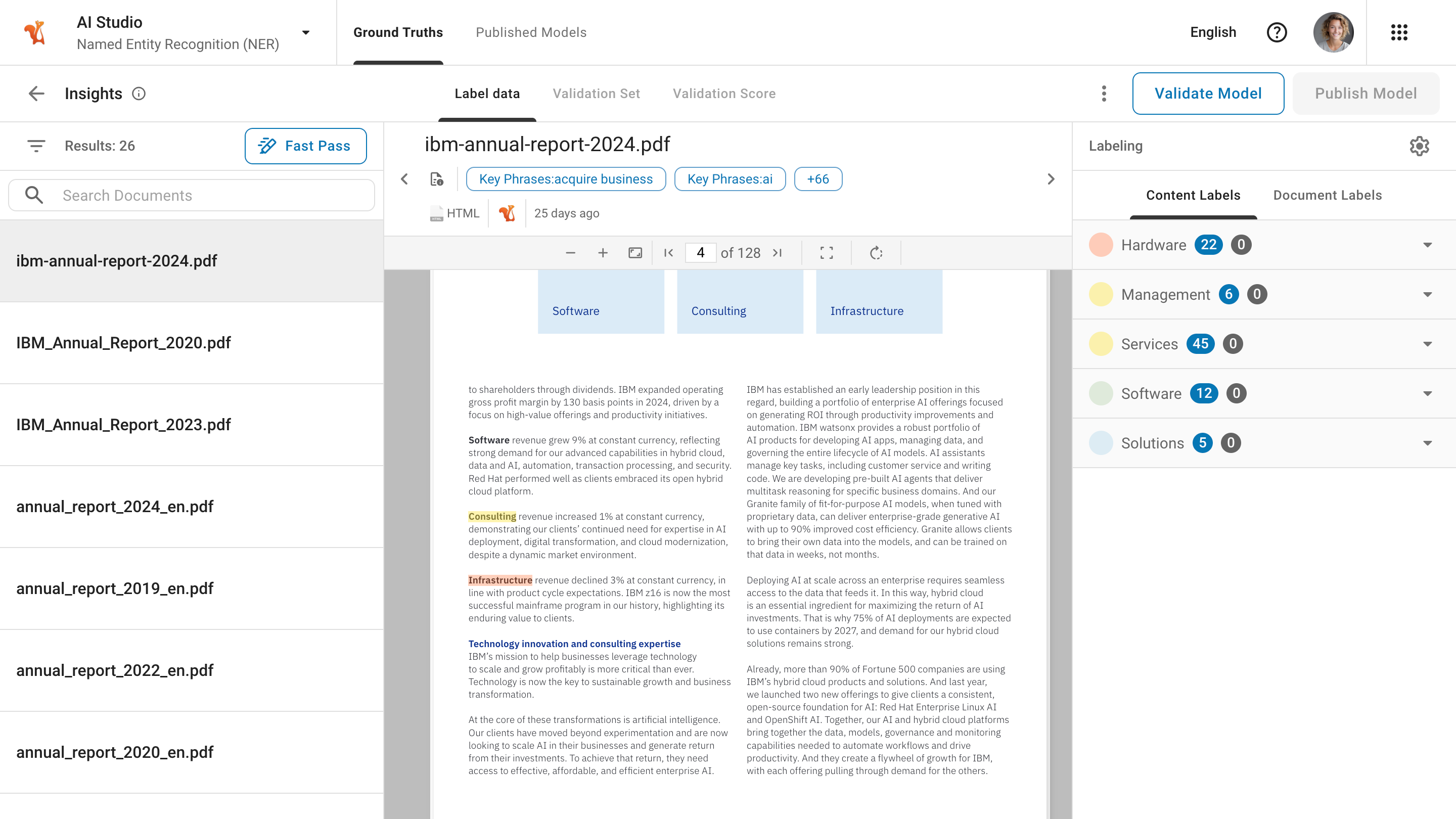
Added support for fetching and integrating remote tools via an MCP server to Squirro Chat.
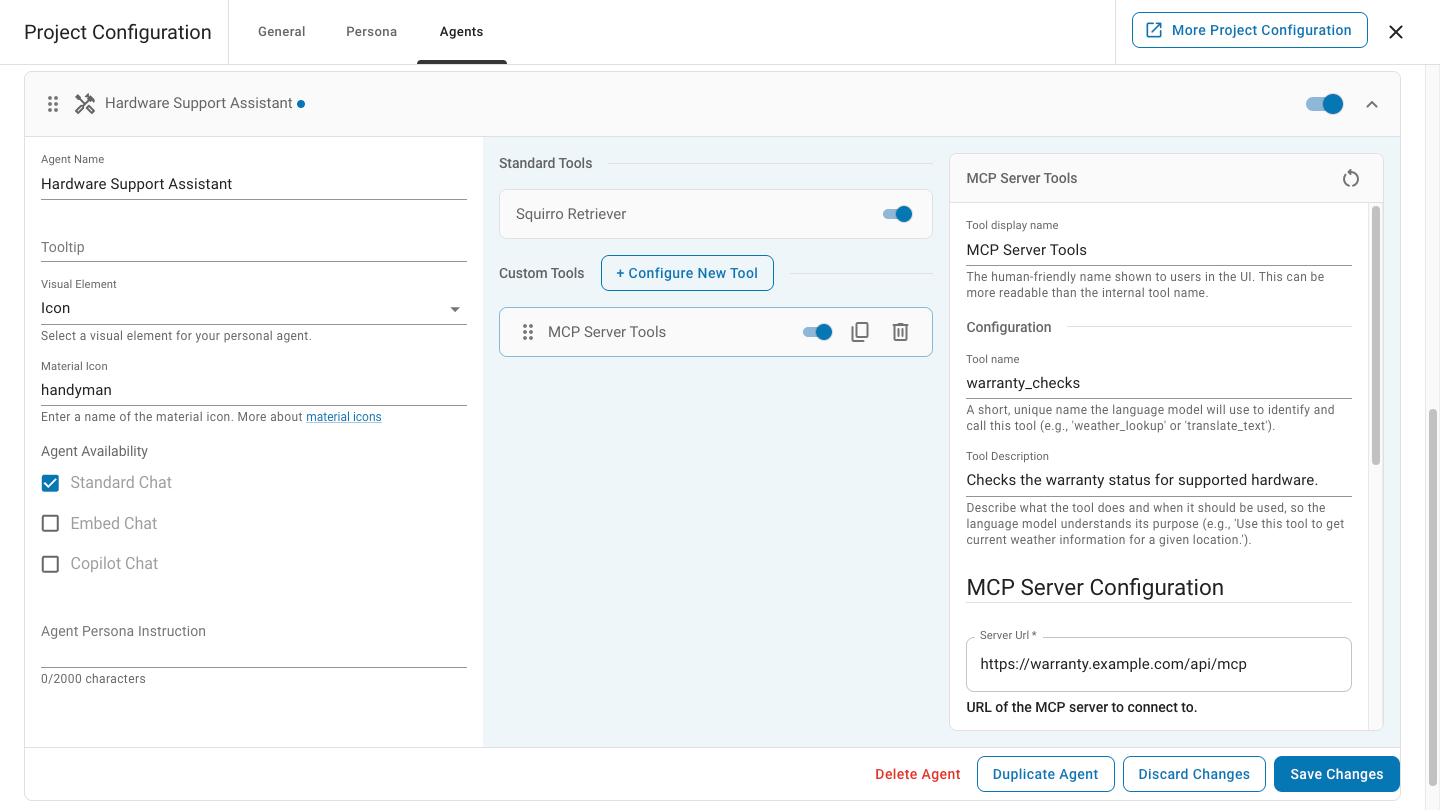
Personally Identifiable Information (PII) detection and masking capabilities.
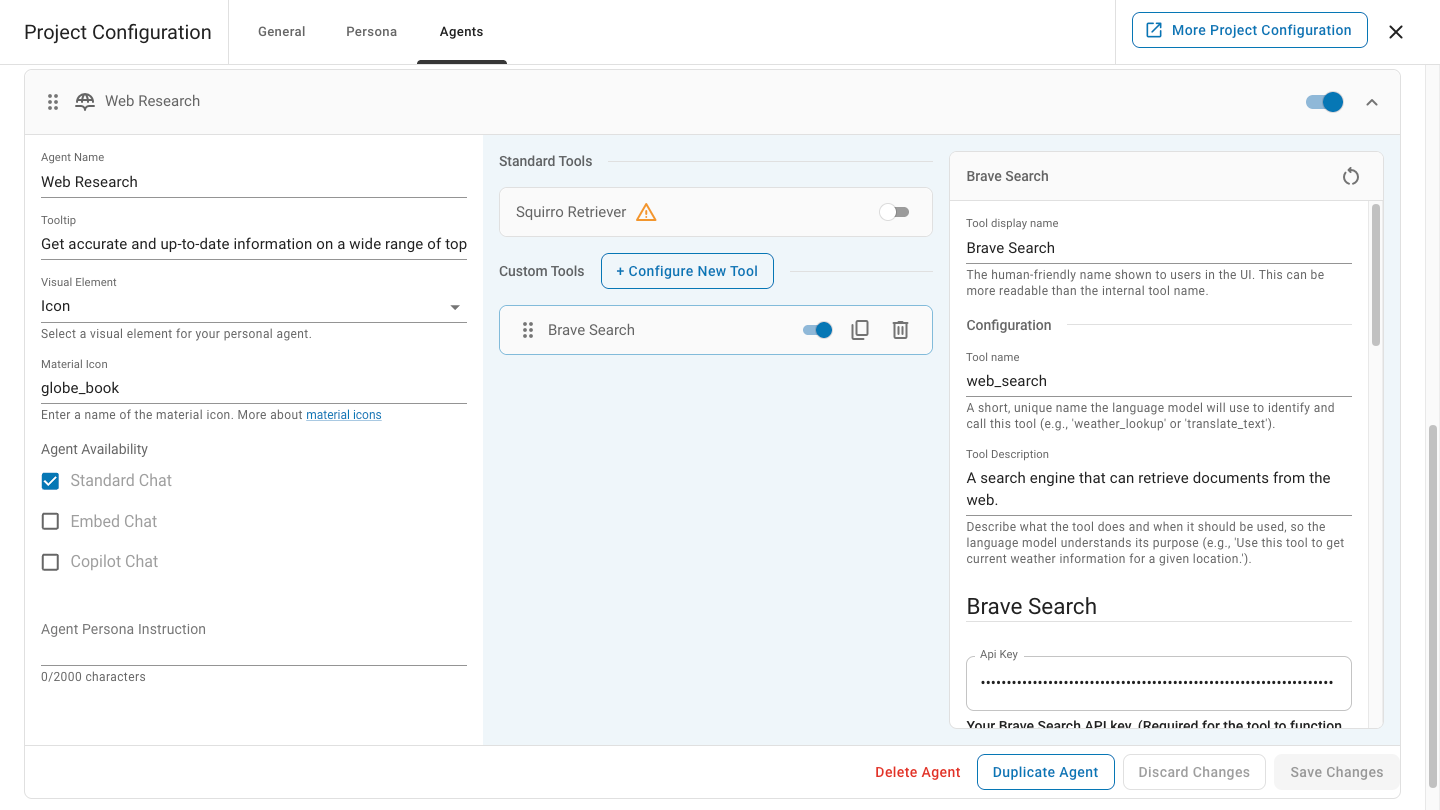
Brave Search Agent for the GenAI service.
Search evaluation studio plugin and framework.
AWS S3 bucket data loader.
Improvements#
AI#
Added validation in toolkit.py to detect unsupported list returns from tool factories with a helpful error message explaining how to split into separate
@deploy_as_agent_toolclasses.Enhanced language configuration to prioritize user preferences over project settings.
Include content optimization metrics showing actual character counts and size distributions sent to the LLM.
Added automatic conversion between frontend timeout values (milliseconds) and backend usage (seconds) with proper fallback handling.
Added post-processing safety net to automatically strip unwanted markdown code blocks from LLM responses.
Created
EnhancedBraveSearchWrapperclass with improved error diagnostics.Modified agent import endpoint to preserve type information by accepting
list[Agent]instead oflist[AgentCreate].Added comprehensive error handling for HTTP status codes (401, 403, 422, 429) with specific user-friendly error messages.
Enhanced
_make_sse_requestfunction to support optional query string parameters.Enhanced timeout configuration to use project-scoped settings instead of hardcoded values, allowing per-project customization.
Changed parameter filtering logs from debug to info level to ensure users are aware when parameters are removed due to model limitations.
Enhanced Brave Search with detailed error logging and user-friendly messages.
Added debug logging for API requests, responses, and JSON parsing.
Maintained embed mode compatibility by skipping user preferences when a token is provided.
Added logging when telemetry is activated via trace commands.
Enhanced agent import logic to only apply upsert behavior to default agent types (all-data, search-results, collection, favorite, chat-with-llm) while preserving existing behavior for custom agents.
Added proper error handling for user preference fetching with graceful fallback.
Applied markdown code block stripping to all summarization chains (
SummarizationChain,GuidedSummarizationChain,ParallelSummarizationChain)Enhanced summarization prompt to explicitly instruct LLMs not to wrap markdown output in code blocks.
Studio Plugins that existed on the AI Studio tab have been moved to the Data tab.
Add
squirro_final_output_structuretelemetry event providing 1:1 correlation with tool output markdown structure for the LLM input verification.Added user preferences fallback logic for assistant language configuration.
Added intelligent parameter filtering for OpenAI reasoning models (o1, o3, o4 series) that have restrictions on
temperatureandtop_pparameters.Added
import_with_upsertmethod toAgentCollectionthat replaces existing default agents by type instead of creating duplicates.Created specialized SquirroClient instances with extended timeouts for GenAI operations (streaming chat, summarization, starter questions).
Implemented helper functions to fetch and parse user preferences from the Squirro client.
Add telemetry parameter support to the
streaming_chatendpoint for enabling GenAI request tracing.Implemented configurable timeout system for the GenAI streaming operations to prevent premature connection timeouts during long-running AI requests.
Add
/traceand/trace-verboseslash commands for easy telemetry activation via the chat interface.Added project-level timeout configuration using
frontend.sqgpt.default-timeoutfor consistency between the frontend and backend timeout handling.Refactored
tool_calling_agentprompt construction to use Jinja templates defined in the agent configuration.API endpoint to query available tools for agents.
Improved customization options for the Chat widget.
Enhanced Squirro Chat agent schema with instructions and prompt fields for per-agent prompt customization.
Expose more configuration on how the retriever should search for relevant information (keyword search, hybrid search, semantic search), how context should be built, and how user instruction should be parsed.
Ability to define a custom toolkit for an agent.
Best paragraph expansion retriever returns explicit message on empty result set.
Improved support of agents filter-query for follow-up chat instructions with document selection.
Added project settings to customize internal squirro-retriever behavior.
Added possibility to provide API keys for all LLM providers via environment variables.
Added
squirro_query_syntax_filterto the retriever settings.Added
retriever_tool_descriptionto the retriever settings.Tool Calling Stabilization to ensure the agent provides required input arguments for the retriever.
Instruct the agent in the tool-response to retry tool calling if no suitable context is found.
Correctly handle missing input parameters for different states (chat-with-item, selection, all data) and user intent (summarization, search).
Allow the selected conversation to persist on refresh.
Encode
chat-stateintosquirro-retrievertool description to make summarization instruction more stable, so that the agent calls the tool also forchat-with-selection.generated_summaryadded to the list of fields returned by the Item Details API.Improve handling of different kinds of filters when chatting with search results and favorites, and with any forward combination with agent filters.
Support for Markdown in the disclaimer text of the Chat widget.
An administrator can configure multiple
squirro-retrieverinstances, each one with custom settings like filtering for a specific data source. Those settings effectively override the default retriever settings defined ingenai.sqgpt.squirro-retriever-settings.Default toolkit specs also created during the creation of default agents.
Support for the o-model family from OpenAI.
additional_filter_querytool option, allowing users to set an extra Squirro query for filtering results, such as targeting a specific data source.Upload
genaiplugins viaSquirroClientorsquirro_asset.
Search#
Add clustering efficiency metrics including clusters per document and paragraphs per cluster ratios.
Replace conditional result sampling with comprehensive full-resultset logging for better observability.
Add pipeline efficiency scoring for performance monitoring and optimization.
Add the filtering by collection profile to the semantic profile.
Inject RNG instance from
kmeans_nativetoinitialize_centroids_kmeans_plus_plusfor better consistency.Add comprehensive telemetry event
squirro_paragraph_search_resultswith detailed search metrics including total paragraphs, unique documents, and clustering predictions.Add
squirro_document_context_assemblytelemetry event to track the paragraph-to-cluster transformation with consolidation metrics and efficiency scoring.Add vector oversampling and rescoring as a default for searches on quantized vector fields - allow users to specify more or less oversampling via the semantic profile plugin options.
Add comprehensive clustering concurrency tests with 11 test cases covering thread safety, race conditions, and deterministic behavior.
Add
squirro_retrieval_pipeline_summarytelemetry event with complete end-to-end transformation overview and per-document breakdown.Introduced a new profile plugin that marks items added after the last user interaction with the
NEWchip.Introduced a new reranker scoring plugin for reranking top-N ranked items using advanced models like ColBERT and LLMs.
Enhanced query building for better result relevance when targeting specific text fields.
Improved search evaluation plugin robustness.
Enhanced reranker plugin to align scores of top-N reranked items with other items outside the rerank window.
Reprocessing items without generating chunks now updates indexed paragraphs with new data like keywords.
New Highlight option for QueryLens.
Disable encoding for
title.<lang>.origquery for exact match queries.Semantic paragraph highlighting improvements.
Add paragraph-scoped search to QueryLens.
Added missing support for
scale_by/mboostinside document-scoring-profile configuration.Added missing support for
rank_by/boostinside document-scoring-profile configuration.The labels widget value search now only appears if there are 8 or more values.
The search service is now accessible via the
/search/serviceURL.
Platform#
Add SSE-specific optimizations by disabling proxy buffering and caching for real-time streaming.
Changed telemetry system from opt-in to opt-out behavior - telemetry is now enabled by default.
Updated telemetry configuration logic to check for disable values (“false”, “0”, “no”) instead of enable values.
Increase proxy timeouts to 5 minutes (read, send, connect) to provide more leeway for large reasoning models.
Enhanced environment variable handling with backwards compatibility support for
SQ_RETRIEVER_TELEMETRY_ENABLED.Add user role in the userproxy service response for the
/v0/user/{user_id}/endpoint.Added filesystem persistence for exception resolved status in JSON format.
Add proper header forwarding (Host, X-Real-IP, X-Forwarded-For, X-Forwarded-Proto) for security and logging.
Add verbosity level metadata to telemetry trace summaries for enhanced debugging context.
Added comprehensive test coverage for error handling scenarios and logging behavior.
Added
pipelineworkflowsto the publish endpoint. Enabling undeploy and unpublish in the Squirro Classifier.Implemented robust ID generation system using SHA256 hash of exception content for consistent identification.
The Data Ingestion Monitoring dashboard, which displays the ingester backlog status, is now workspace-scoped. It means it only shows the backlog for sources that exist in projects belonging to the selected workspace.
Preserve chronological order of the event types in the trace summary based on the first occurrence.
Enhanced NER validation workflow to support marking exceptions as resolved, removing them from the UI display.
Add cache for audit logging when user information comes from the userproxy service.
Improved on existing ES maintenance tooling and added a new
migration_managertool to assist with reindexing a large number of ES indices to render them compatible with a new ES version.Sort telemetry trace events chronologically by timestamp to ensure logical debugging flow.
Add
_extract_all_document_metadata()helper function for comprehensive document tracking with inclusion status indicators.Auto-generate 8-character hash-based unique IDs for existing exceptions to maintain backward compatibility.
Add resolved status to the NER validation set exceptions with unique ID generation.
Implement PUT endpoint
/validations/{validation_id}/exceptions/{exception_id}across all API layers (ML Service → Topic API → Python Client).Add comprehensive validation and error handling for exception updates with proper permission checks (ml.ner.validations.write.update).
New configuration type called
secretfor encrypted, write-only entries for project and server configurations.Enhanced cleanup of temporary directories and improved clarity on component creation.
Now explicitly exits Phase 2 when questionnaire is empty and proceeds to Phase 3.
Rate limit exceptions are propagated to the service caller via SSE stream.
Allow specifying SSL-related variables via environment.
Upgraded Elasticsearch server and Python client versions.
Add configurable white/black (allowed/denied) lists of sites/subsites for Enterprise MS SharePoint data loader.
Removed administrator requirements from start pages after project creation.
The Data Ingestion logs are now indexed in workspace-scoped indices, enabling data isolation between Squirro Monitoring projects in different workspaces.
Parallel steps now log the exit status as
errorin the batch-level End message if at least one item in the batch has failed.Enhance PDF conversion structured logs by including
item_idand exposing LibreOffice error messages.Added new endpoints for automated monitoring of Squirro project health.
When the PDF Conversion step fails to convert an item and its
ignore_errorsoption is enabled, the item is assigned a Processing Error label with the error code “SQ-05107”.The Google Drive connector now supports including folder name information for each file using the label
folder_name (Folder). The new advanced config optionresolve_full_folder_pathcontrols what information is stored: when enabled, files include their full folder path using the dot notation. Otherwise, only the name of the direct parent folder is included. For example, if a file is stored underMy Drive.Animals.Squirrels, the folder name will beMy Drive.Animals.Squirrelsif this option is enabled, andSquirrelsif it is not.Support for SharePoint Lists.
Adjusted JavaScript code and function calls to enhance security and improve page performance.
Preloading capabilities for the chat widget.
Stabilized paragraph highlighting by displaying full paragraph bodies in the left pane (sidebar) and generating more and longer sentence fragments, which are used to improve sentence highlighting in PDFs.
The
Content Extractionstep removes soft hyphens from the extracted text.Data Ingestion structured logs now include the
hostnameandprocessor_namelabels for better traceability.hostnameis the hostname of the node where the ingester processor was running andprocessor_nameis the name of the ingester processor that emitted the log (for example,processor_1unstructured logs are located at/var/log/squirro/ingester/processor_1/processor.log*).The
Indexingstep now always emits anEndbatch structured log, including the raised exception when it fails to process the batch.Ability to copy ID to clipboard for sources, pipelines, and items.
Paragraph Highlighting of Cited Documents: Moved to the LLM-driven selection of best paragraphs (dynamically populated paragraph-highlighting hyperlinks). Before, the first paragraph in the
context-sectionwas highlighted (confusing users), now the most relevant paragraph (according to the LLM) is highlighted.Access studio plugins for a workspace admin.
The Google Drive connector now exports Google files (Docs, Sheets, Slides, Drawings) to their respective OpenDocument formats (ODT, ODS, ODP) and SVG by default. The ability to export these files to PDF using the Google Drive API is now available as an advanced configuration option.
Support map in chat widget chart output.
Make
SQUIRRO_GIDmatch the user GID in thesqgenaicontainer.Change the height of the search bar in default dashboards so it is not cut off.
Load item detail on chat open.
Added exist endpoint which gives item ids, efficiently checks if the ids are in the index and returns a dictionary in format
{ "item_id": bool }(True if present, False if not)Updated the Squirro Python client to include access to search service endpoints.
Decorator for logging structured audit information about HTTP requests and responses. The new server-level configuration option
security.audit-loggerenables the audit logger for allapi.userand some project-relatedapi.topicendpoints.
Bug Fixes#
Fix issue where, in some cases, the groups of a cluster admin user could not get updated.
Fix user being added to a different workspace than intended.
Highlight color can now be changed in the Squirro Classifier categories.
Add missing source_type facet defaults (analyzed, searchable and ` typeahead` set to True).
After reseting the Chat widget user settings, the interface language might not be shown in the selection.
Fixed agent duplication during project import operations.
Fixed an issue where the perform_only_knn semantic search option would result in unexpected extra results ending up in the result list.
Fixed summarization caching which was not working on non-Workspace instances.
Fix date detection and query rewriting.
Vector searches are now consistent between repeat searches.
Fix an issue with recently introduced
append_keywords_to_paragraphs_on_absent_chunksindex option which caused updating paragraphs to fail.Fixed malformed JSON structure in
settings.jsonby movingfrontend.sqgpt.enabledandfrontend.sqgpt.default-timeoutentries to the root level to correct improper nesting.Fixed AI summary markdown formatting issue where summaries were displayed as raw markdown instead of formatted content.
Fix file-based data sources for cluster readers who are workspace admins.
Fix
AttributeErrorin the telemetry pipeline summary whencluster_infoisNoneby ensuring proper null value handling.Fix document-level exceptions not being returned when validation is executed.
Fix line chart legend not rendering label with value 0.
Fix workspace admin not being able to access certain studio plugins.
Replace thread-local RNG with local RNG in async clustering to fix race conditions in async/await environments.
Fix embed chat shown as small when it is set to large only.
Fixed
temperatureandtop_pparameters being omitted when set to default values (0 and 1 respectively). Previously, explicitly settingtemperature=0would result in OpenAI using its default temperature (0.7) instead of the user-specified value.Assistant language set in user preferences is now properly respected across all GenAI endpoints.
Get user information (user email and user cluster role) from the
userproxyservice, request parameters or request body.In the Left sidepanel, Best Paragraph Highlighting only worked for english documents before. This is now fixed and works reliable across all languages.
Fixed issues with synonym updates when the synonym list is empty.
Improved handling of items that failed during pipelet execution by retrying them.
Resolved issues with JSON form saving and closing after each keystroke in project and server configuration pages.
Fixed parsing errors in Scoring Profile Syntax with empty arguments.
Corrected feedback display in the help menu.
Fixed search score calculation errors in specific scenarios.
Fixed language options in Squirro Chat when
frontend.userapp.languagessetting is empty.Improved custom facet formatting for widget display.
Wrong prompt added to paragraphs-to-be-embedded, potentially impacting retrieval quality.
Allow for user selection on Microsoft side before authentication to SharePoint plugin.
Handle empty responses from Redis when no queued items are found.
Fix issue with the
ItemIndexReader.read_itemmethod whenproject_idis empty.Fix being redirected to log in after logging out from cloud instances.
Fix
project_idbeing None when attempting to call function requiringproject_id.Fixed reranker deleting certain results when it should be a no-op.
Add missing current date to the system prompt.
Fix genai SQL user database not getting created when installing genai service.
Fix custom widgets parent rendered multiple times, preventing clicks.
Ensure
genai_readeruser is added to workspace before project.Ensure using a refresh token in query parameters doesn’t fetch all EMBED chat conversations.
Remove the Sales Insight template from existing deployments.
Extracted request logic to function for authentication with Flask request context.
Fixes current date injection in RAW tool.
Fixed chat with document not retrieving the overall item context.
Fixed an issue where chat with document did not have all the tools available.
Date filters incorrectly applied to the paragraph expansion retriever.
Chat user settings show unsupported project languages in the interface language selector.
Ensure that the default toolkit is used if no toolkit is defined.
Fix relaying runtime parameters for agent-defined tools.
Duplicating dashboard sometimes creates a default dashboard.
Show limited My Account page for workspace user/admins.
Ensure cleanup of the temporary directory on failed requests of KEE POST /save.
Fix an issue where attempting to highlight based on a certain paragraph ID using the paragraph_highlight plugin would cause 0 results to be returned - thus breaking following the referenced documents in chat.
Remove locally stored content files for data batches that failed indexing.
Update by query sends now a parameterized painless script, which avoids too many script compilations.
Cluster Reader / Workspace Admin cannot create a new project.
Ensure the subitem ID generation produces stable identifiers. It prevents multiple sub-item documents from being created in the index when the same item is ingested multiple times.
Fix indexmanager’s GET /cluster/health endpoint after ES client upgrade.
Resolved an issue with the Data Ingestion Monitoring dashboard where a backlog from a deleted data source caused errors.
“Cloud” menu now shows even when
workspacesis disabled.Fixed an issue where using
scale_byclauses with a semantic clause andperform_only_knnset totrueresulted in a query returning zero results.Removed unused template usage in
CommunitiesWidget.RTE widget toolbar is not always visible.
Incorrect count showing for labels widget in single dropdown mode.
genaiAlembic migration not working on Postgres database when upgrading fromgenai<=3.12.1togenai>=3.13.0.Date time selection popup cut off on small screens.
Mechanism to check environment variables exist and are not empty.
Access to Studio plugins in the Workspace space for Workspace Admins with Cluster User role.
Reselecting space loading via
href.Instances of
andin a phrase parsed as a boolean operator.Squirro Monitoring project creation in workspaces that existed before the deployment of the new workspace-scoped data ingestion logs indices.
The monitoring project link from the spaces selector not specific to its workspace.
Temporary directories matching
lu<soffice_pid><id>.tmp, created by thepdfconversionservice, not removed after unsuccessful conversion.Correct handling of the chat filters for the agent query and dashboard.
Nonevalues not ignored when updating the current settings.
Miscellaneous#
Rework studio plugins permissions check for a cluster with Workspaces activated.
Known issues#
In specific scenarios, cross-lingual information retrieval for semantic search may deliver lower-than-expected quality (SQ-28171).
When closing the Project Configuration dialog in the chat dashboard, a “Discard changes” modal may appear even when no changes were made (SQ-29386).
Breaking Changes#
Elasticsearch upgraded to version 9. Elasticsearch indices created with version 7 are not compatible with version 9 and must be reindexed. Refer to the Elasticsearch Migration page for detailed instructions on migrating Elasticsearch indices. Attempting to upgrade Squirro without reindexing will result in errors.
For custom deployment YAMLs for the
genaiservice, manual updates are required to enable PII configuration via project settings. Default deployment setups work out of the box.Environment variable names of
genaiservice Docker image have been changed to unify syntax: -SQUIRRO_CLUSTER→SQ_CLUSTER-SQ_GENAI_DB→SQ_DATABASE_URL-SQ_GENAI_DB_SSL_CA→SQ_DATABASE_SSL_CADrop support for Python 3.8 in the Squirro SDK
Drop support for Python 3.8 in the Squirro Client
Removed
squirro.common.tracing.elasticsearch_tracingmodule, as Elasticsearch tracing is now handled by the Elasticsearch Python client. Tools that rely on this module should be updated to not use this module anymore.Setting an additional query on the agent is no longer supported, use
additional_filter_queryon the Squirro retriever instead.Introduced
SQ_SECURITY_WORKSPACESenvironment variable forgenaiservice Docker image that is required for some platform-related features like document summary storage and ML workflows execution. The value must be the same as the value ofsecurity.workspacesfor the connected Squirro Platform (which isfalseby default).The Default grounding mode configuration setting offering the choice between strict or lenient no longer exists in the project configuration in Squirro Chat. The system now enforces the strict mode by default at the tool level when configuring an agent and applies it automatically without user intervention or control.
The behavior of the
streaming_chatendpoint changed. Previously, if noagent_idwas provided in the payload, thesquirro_retrieverwould be called, meaning answers would be based on the context retrieved. Now, if noagent_idis provided, no tools are used (sosquirro_retrieveris not called). In order to have answers based on the context retrieved by thesquirro_retriever, theagent_idfield of the payload should be set to the ID of an agent withsquirro_retrieverin its toolkit. That change only impacts direct calls to the GenAI API if they do not supply anagent_idvalue with the request. The overall behavior of Squirro Chat is not impacted as with every request it sends anagent_idvalue.External website integrations using the embedded chat widget require updates to the embed code. To implement these changes, you need again to copy and paste the updated Squirro Chat code into the
<head>element of your website or application. You can find the updated code under the Setup/Installation tab of the Embed Digital Assistant as a Floating Action Button configuration wizard.
Installation and Upgrade#
For new installations, find step-by-step instructions on the Install and Manage Squirro with Ansible page (recommended) and Installing Squirro on Linux pages.
To upgrade an existing installation, see the Upgrading Squirro page.